La computación cuántica es el tema esotérico de moda en informática teórica y práctica. Este post trata sobre ella desde el atrevimiento que da la ignorancia, pues actualmente nadie comprende la física cuántica en su totalidad, y mucho menos yo, pero sí es posible explorar sus fascinantes posibilidades. He estructurado el texto desde lo menos técnico a lo más técnico intentando evitar las ecuaciones hasta el final de modo que cada cual pueda leer hasta donde le interese.
Motivación y aplicaciones de la computación cuántica
El orígen de la computación cuántica se atribuye a Paul Benioff y Yuri Manin en 1980, y a un artículo de Richard Feynmann en 1981 en el cual sugirió que dado que es extraordinariamente difícil simular el comportamiento cuántico con ordenadores convencionales entonces una forma mejor de estudiar modelos de la realidad sería fabricar ordenadores cuánticos. Grosso modo la complejidad del problema estriba en que en un sistema cuántico las partículas y sus interacciones no pueden considerarse por separado como si fuesen bolas en una mesa de billar sino que hay que tratar todo el sistema en conjunto.
Los estudios sobre la viabilidad práctica de construir dispositivos computacionales que usen efectos cuánticos se remontan a hace ya más de una década, pero desde que recientemente Lockheed Martin, Google, la NASA y la CIA se interesaron por el producto de la empresa D-Wave, las publicaciones como Wired se han plagado de artículos sobre los dispositivos computacionales cuánticos presuntamente venideros. Quiero enfatizar el término dispositivo computacional versus ordenador porque hoy por hoy no existe tal cosa como un ordenador quántico, sólo existen máquinas que ejecutan determinados algoritmos concretos utilizando efectos cuánticos para acelerar la resolución de problemas especialmente difíciles de resolver con algoritmos clásicos.
La computación cuántica no revolucionará a corto plazo la informática en nuestros hogares pero podría catalizar avances científicos que influirían enormemente en nuestras vidas cotidianas. La razón de que la computación cuántica esté limitada a centros de cálculo es que lo más parecido que existe actualmente a un ordenador cuántico es una nevera gigante cuyo interior está a 20 milikelvis. Es por ello que el modelo de negocio de supercomputación cuántica se orienta más hacia SaaS que hacia la venta de hardware.
La computación cuántica no hará (por ahora) que nuestros emails se abran más rápido ni que los gráficos de los juegos mejoren. Pero podría servir, por ejemplo, para descubrir materiales superconductores a temperatura ambiente. O también podría usarse para encontrar un método de fabricación de fertilizantes mejor que el método de Haber que data de 1905 y en el que según las estimaciones se emplea actualmente entre el 3% y el 5% del gas natural y entre el 1% y el 2% de toda la energía producida por el hombre. Por consiguiente, encontrar un proceso industrial capaz de fijar el nitrógeno en amonio como hacen los diazótrofos supondría un gran ahorro de energía y emisiones de CO2. Pero las simulaciones de las reacciones químicas requeridas para fijar el nitrógeno ambiental son demasiado costosas computacionalmente para un ordenador convencional.
La mayoría de los ejemplos de aplicación se centran en problemas de optimización como encontrar el tratamiento de radioterapia óptimo para eliminar un tumor causando el mínimo daño colateral al paciente. Aunque existen dos excepciones notables: las aplicaciones en inteligencia artificial y el ataque a sistemas criptográficos. Esta última aplicación ha atraido mucha atención pues los algoritmos DSA y RSA con los que está encriptado la gran mayoría del tráfico de Internet son vulnerables a ataques por un computador cuántico lo bastante potente (que actualmente no existe). Por consiguiente, tanto gobiernos como grandes empresas están muy interesados en controlar la computación cuántica, o al menos una parte de ella, y ya existen muchas patentes sobre algoritmos y tecnologías cuánticas aplicadas a la computación.
Limitaciones cuánticas de los ordenadores digitales
Una de las predicciones futurológicas más acertadas de los últimos 50 años es la Ley de Moore. Enunciada en 1965 predijo que el número de transistores en un microprocesador se duplicaría aproximadamente cada 24 meses. Y se ha cumplido con una precisión sorprendente. Sin embargo, la predicción está peligrosamente cerca de un límite de posibilidades de producción.
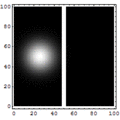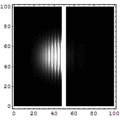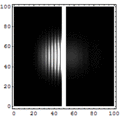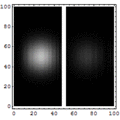 Para meter más transistores en un microprocesador lo que se hace es reducir el tamaño de los transistores. Actualmente, los transistores más modernos se fabrican con tecnología de 14 nm (1nm = 1 mil millonésima de metro). Puede que se consigan alcanzar los 5nm en 2020. Pero a medida que se reduce el tamaño es más complicado disipar el calor y además se producen efectos de tunel cuántico debido al cual una parte de la corriente eléctrica puede saltar de un circuito a otro a través de un aislante. En la animación es posible observar cómo la función de onda de un electrón traspasa una barrera de potencial. Cuando la barrera es grande la probabilidad de que el electrón salte es a efectos prácticos cero, pero a medida que se reduce el tamaño los saltos por túnel cuántico deben realmente empezar a ser tenidos en cuenta. Como es imposible evitar los efectos cuánticos lo que hacen los ordenadores cuánticos es tratar de sacar partido de ellos.
Para meter más transistores en un microprocesador lo que se hace es reducir el tamaño de los transistores. Actualmente, los transistores más modernos se fabrican con tecnología de 14 nm (1nm = 1 mil millonésima de metro). Puede que se consigan alcanzar los 5nm en 2020. Pero a medida que se reduce el tamaño es más complicado disipar el calor y además se producen efectos de tunel cuántico debido al cual una parte de la corriente eléctrica puede saltar de un circuito a otro a través de un aislante. En la animación es posible observar cómo la función de onda de un electrón traspasa una barrera de potencial. Cuando la barrera es grande la probabilidad de que el electrón salte es a efectos prácticos cero, pero a medida que se reduce el tamaño los saltos por túnel cuántico deben realmente empezar a ser tenidos en cuenta. Como es imposible evitar los efectos cuánticos lo que hacen los ordenadores cuánticos es tratar de sacar partido de ellos.
¿Qué es la computación cuántica?
No es posible entender el estado del arte de la tecnología de computación cuántica sin entender previamente qué es un sistema cuántico. Para quién esté interesado en los fundamentos matemáticos de la mecánica cuántica la mejor introducción que yo he encontrado es la de Susskind y Friedman. También hay sendos capítulos sobre física cuántica en la monumental obra de Penrose El Camino a la Realidad. El curso sobre computación cuántica más completo que he podido encontrar es el de Michael Loceff. Sobre probabilidades cuánticas el texto de Greg Kuperberg. Y la tesis de tesis doctoral de Mario Mastriani también es bastante didáctica.
 Pero empecemos pues con los fundamentos de la computación cuántica.
Pero empecemos pues con los fundamentos de la computación cuántica.
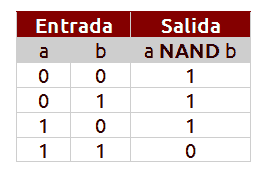
En un ordenador convencional la información se representa como cadenas de bits 0 o 1. En cada instante del tiempo, el estado del ordenador lo describen en su totalidad los estados de sus bits. Por ejemplo, en un sistema de dos bits, el conjunto de todos los estados tiene 4 elementos y es {00, 01, 10, 11}. El sistema cambia de un estado a otro haciendo pasar los bits por puertas lógicas. Por ejemplo, una puerta es NAND cuyas entradas y salidas son las mostradas en la tabla. NAND es una puerta lógica universal mediante la cual se pueden construir las otras puertas lógicas de dos bits AND, OR, NOR, XOR, XNOR mediante combinaciones de puertas NAND.
En un ordenador cuántico la información se almacena en qubits. La diferencia entre un bit y un qubit es que el qubit puede encontrarse en un estado intermedio entre 0 y 1 con una probabilidad respectiva para cada valor que en conjunto deben sumar el 100%. Para distinguir los estados cuánticos de los clásicos los escribiremos como |0⟩ y |1⟩ Esta notación se conoce como vectores ket, pero no nos interesa entrar ahora en lo que son matemáticamente los ket. Una forma de imaginar el qubit es como un átomo con un electrón que tiene dos niveles de energía (estados) |0⟩ y |1⟩
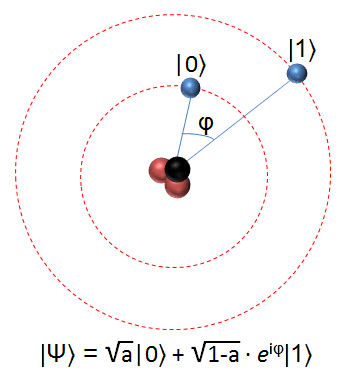
En cada instante del tiempo el átomo (qubit) se encuentra en una superposición de los estados |0⟩ y |1⟩ Sin embargo, cuando se realiza una medida el estado se colapsa a un valor 0 o 1. La evolución de los estados es un proceso totalmente determinista que se puede predecir, pero la información disponible al observador son sólo las probabilidades de encontrar el qubit representando |0⟩ o representando |1⟩ en cada momento.
En la ecuación del gráfico, además, los estados están separados por una fase denotada por la letra griega phi (φ) cuyos detalles no comentaremos aquí.
Según esto, la información que almacena un sistema cuántico es mucho mayor que la que almacena un sistema digital clásico, ya que no sólo contiene cero o uno sino una descripción de la probabilidad de que cada bit se encuentre en cero o uno al realizar una medida.
En sistemas de dos o más qubits, algunos qubits podrían formar un único sistema en lo que se conoce como entrelazamiento cuántico. Si este es el caso, entonces no es posible modificar el estado de un qubit sin alterar el estado de los otros qubits entrelazados.
Para un sistema con tres qubits los estados se representarían con un vector de 8 dimensiones:
a|000⟩ + b|001⟩ + c|010⟩ + d|011⟩ + e|100⟩ + f|101⟩ + g|110⟩ + h|111⟩
donde los coeficientes a…h son números complejos y la probabilidad de encontrar al sistema en cada estado es el cuadrado de la norma de cada coeficiente complejo |a|²…|h|² La norma de un número complejo z se escribe |z| y si z = x+yi entonces la norma |z| = √x²+y²
El sistema no puede evolucionar de forma arbitraria sino que la evolución debe mantener ciertas propiedades, la más importante que la suma de probabilidades |a|²+|b|²+…+|h|² debe ser siempre igual a 1.
El criterio de DiVincenzo
En el año 2000, David P. DiVincenzo publicó un trabajo breve pero muy citado titulado The Physical Implementation of Quantum Computation en el cual enumera cinco requisitos para que un ordenador pueda funcionar basándose en efectos cuánticos:
1. Capacidad para operar con un número fucientemente grande de qubits bien caracterizados.
2. Posibilidad de inicializar el estado de cada qubit con probabilidades arbitrarias de |0⟩ y |1⟩.
3. Tiempos de vida (decoherencia) de los qubits lo bastante largos.
4. Un conjunto «universal» de puertas lógicas cuánticas.
5. Posibilidad de medir el estado de cada qubit individualmente.
Desafíos técnicos que presentan los qubits
Todos los sistemas que tratan de explotar las propiedades cuánticas de los qubits se enfrentan a las dificultades enunciada por DiVincenzo.
En primer lugar es facilísimo que el estado cuántico de un conjunto de qubits se colapse a un valor determinado debido a un fenómeno conocido como decoherencia por el entorno que se produce debido a la más mínima perturbación térmica o magnética en el qubit. Actualmente, el estado del qubit sólo puede mantenerse durante unas pocas decenas de microsegundo. Además, cuantos más qubits entrelazados hay más dificil es prevenir la decoherencia. Algunos teóricos piensan que la decoherencia de un sistema cuántico se produce de forma inevitable por efecto de la gravedad. Si eso es cierto, siempre existirá un límite de tiempo no muy largo en el que se pueda mantener el estado de un qubit ya que no es posible aislar un sistema de la gravedad.
En segundo lugar no es posible leer el estado de un sistema cuántico sin dejar el sistema en un estado desconocido. Es decir, se puede saber en qué estado se encontraba el sistema antes de la lectura pero no se puede saber en qué estado habrá quedado después de ella. Esto implica que no se pueden fabricar puertas lógicas cuánticas igual que las convencionales porque, entre otras cosas no es posible clonar el estado de un qubit.
En tercer lugar existe un serio problema de detección y corrección de errores. La corriente utilizada en los qubits implementados con superconductores es del orden de 10 microvoltios con una diferencia de energía entre el estado |0⟩ o |1⟩ de 10-24 julios. Esto es diez mil veces menor que el nivel de energia que separa un 0 de un 1 en un ordernador digital. Por consiguiente, en un ordenador cuántico es mucho más difícil distinguir un |0⟩ de un |1⟩ Pero es que para empeorar la situación aún más recordemos que los qubits sólo están en cada estado con una cierta probabilidad. No es posible en la práctica fabricar dos circuitos superconductores que representen qubits idénticos. Ante la misma señal de reseteo, cada qubit cambia a un estado con distribución de probabilidad entre |0⟩ y |1⟩ ligeramente diferente de los otros qubits. Mediante laboriosos procesos de calibración y manteniendo los qubits lo más aislados de perturbaciones térmicas y electromagnéticas se intenta que todos los qubits se comporten igual. Pero al cabo de una sucesión de operaciones siempre quedará alguna pequeña diferencia estadística en su comportamiento. Tanto es así que en el primer D-Wave instalado para Lockheed Martin sólo están operativos 108 de sus 128 qubits.
Como colofón al problema, recordemos que no es posible leer el estado de un qubit sin destruirlo, de modo que el sistema de corrección de errores debe funcionar prediciendo y corrigiendo errores que aún no se han producido. Una posibilidad es, por ejemplo, representar cada valor 0 o 1 con tres qubits que deberían ser |000⟩ bien |111⟩ Entonces es posible averiguar si el primer bit es igual al segundo. Esto no requiere medir el estado (lo cual lo destruiría) sino sólo la diferencia entre el primer bit, el segundo y el tercero que sí es posible sin destruir el estado. Pero como la comprobación de errores también está sujeta a las leyes cuánticas es posible que se produzcan errores durante el chequeo de errores. El mecanismo de detección y corrección de errores es pues bastante complicado y absolutamente necesario.
Algunos piensan que los ordenadores cuánticos basados en puertas lógicas nunca llegarán a funcionar debido que la tasa de errores debería estar en algún lugar entre uno entre diez mil y uno entre un millón de operaciones para que la corrección de errores fuese eficaz. Por otro lado, el teorema del umbral cuántico afirma que un computador cuántico puede emular a una clásico siempre y cuando la tasa de errores se mantenga por debajo de cierto umbral. Y puede encontrarse un esbozo de cómo funciona la correción de errores en los prototipos de IBM este artículo. Por último, investigadores de Google y UCSB también han publicado resultados sobre la corrección de errores en qubits.
Tecnologías para implementar qubits
Existen tres grandes líneas de investigación financiadas por grandes empresas: la de IBM, la de Microsoft y Bell Labs y la de D-Wave y Google. También se está desarrollando una intensa investigación teórica y práctica en universidades de todo el mundo.
Las tecnologías principales que están siendo investigadas por las grandes empresas para implementar qubits son:
• iones atrapados en campos electromagnéticos
• electrodos superconductores acoplados mediante uniones de Josephson (transmon)
• qubits topológicos mediante aniones no abelianos
Existen también otras líneas prometedoras de investigación como por ejemplo:
• qubits atrapados en imperfecciones diamantinas
• codificación de qubits en fotones
La línea de investigación más audaz es la de Microsoft Station Q que está apostando por qubits topológicos basados en unas hipotéticas partículas llamadas aniones no abelianos que no son ni fermiones ni bosones y que pueden llevar unidades fraccionarias de carga. Si existen, los aniones no abelianos podrían proporcionar una forma de crear qubits extraordinariamente más resistentes a errores que los basados en iones atrapados o microcorrientes. Pero es que además de existir los aniones (lo cual por ahora no está nada claro) debería ser factible moverlos por circuitos supercondutores dispuestos en forma de trenza.
Los Bell Labs también están investigando qubits topológicos contenidos en cristales ultrapuros de arseniuro de galio.
En el caso de ser realizables, los qubits topológicos aventajarían muy probablemente al resto de aproximaciones tecnológicas al ofrecer tiempos de decoherencia en dias en lugar de microsegundos y una tasa de errores varios órdenes de magnitud inferior.
D-Wave
Las únicas máquinas de computacion cuántica comercialmente disponibles por ahora, las D-Wave, usan anillos superconductores de niobio y uniones de Josephson para implementar los qubits. El estado |0⟩ o |1⟩ lo determina la dirección dextrógira o levógira de una microcorriente en el equivalente a un anillo superconductor.
Los retículos de proceso del D-Wave están compuestos de grupos de 8 qubits parcialmente acoplados entre ellos y con los qubits de otro grupo. Inicialmente el sistema se inicializa con cada qubit en una probabilidad 50%-50% de encontrarse como 0 o 1 al realizar una medida. A continuación se puede aplicar un sesgo (bias) a cada qubit para modificar su probabilidad de encontrarse en estado 0 o 1 al medirlo.
Los acopladores permiten definir entrelazamiento entre dos qubits. El efecto del entrelazamiento es asegurar que dos bits tienen bien el mismo valor al realizar una medida bien el valor contrario. Es decir, es posible especificar que si al qubit A devuelve valor 0 al ser medido entonces el qubit B también devuelve 0. O que si el qubit A devuelve 0 entonces el qubit B siempre devuelve 1.
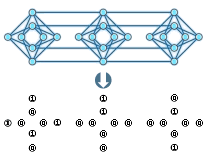 Los D-Wave no son computadores cuánticos universales y en particular no pueden ejecutar la parte cuántica del algoritmo de Shor. Los D-Wave no son programables como un ordenador convencional. Solo permiten especificar el valor del bias y los acoplamientos entre qubits mediante matrices en Python o C. Con estos valores se crea un «paisaje» en el que el D-Wave busca un mínimo usando el algoritmo de temple cuántico descrito más adelante. El estado evoluciona desde la incertidumbre total del valor de cada qbit hasta un 0 o 1 en cada qubit medido, que representa la solución al problema especificado (gráfico derecho).
Los D-Wave no son computadores cuánticos universales y en particular no pueden ejecutar la parte cuántica del algoritmo de Shor. Los D-Wave no son programables como un ordenador convencional. Solo permiten especificar el valor del bias y los acoplamientos entre qubits mediante matrices en Python o C. Con estos valores se crea un «paisaje» en el que el D-Wave busca un mínimo usando el algoritmo de temple cuántico descrito más adelante. El estado evoluciona desde la incertidumbre total del valor de cada qbit hasta un 0 o 1 en cada qubit medido, que representa la solución al problema especificado (gráfico derecho).
La presunta aceleración cuántica de los D-Wave ha sido objeto de un intenso debate con posiciones desde la de Matthias Troyer y otros quienes afirman que no han encontrado evidencias de aceleración cuántica hasta tests de Google que afirman que el D-Wave es hasta 100 millones de veces más rápida que un ordenador convencional en la resolución de problemas cuidadosamente escogidos. Lo que si está claro es que nadie considera la D-Wave como una máquina que sea útil en solitario. El uso que el propio fabricante propone es usar un superordenador para preparar determinados problemas de optimización y delegar su resolución en el D-Wave.
Hay una docena de videos cortos y asequibles que explican cómo funciona el D-Wave publicados por el fabricante en su canal de Youtube.
Clase de complejidad BQP
Antes de entrar a estudiar algunos algoritmos, nos detendremos brevemente a comentar la computación cuántica desde el punto de vista de la teoría de complejidad computacional. Por ahora, parece que las aplicaciones de la computación cuántica serían abordar problemas que pertenecen a la clase de complejidad BQP (bounded error quantum polynomial time) que es el análogo cuántico de la clase BPP (bounded-error probabilistic polynomial time). Hay que recordar que todos los algoritmos cuánticos son probabilísticos, es decir, devuelven la solución correcta a un problema sólo con una cierta probabilidad, que puede ser lo bastante elevada y en todo caso mayor de un tercio en todas las ejecuciones del algoritmo. Se sabe que existen problemas BQP que probablemente no son P, es decir, que no pueden resolverse en un tiempo polinómico respecto del tamaño de los datos de entrada con un ordenador convencional pero sí con un ordenador cuántico. Algunos ejemplos son la factorización de enteros que comentaremos más adelante y encontrar el polinomio de Jones. La relación entre BQP y la clase NP (no polinómicos) es desconocida aunque se cree que los problemas NP Completos no pueden ser resueltos en tiempo polinómico por un algoritmo de clase BQP.
Algoritmos cuánticos
Hay en curso una discusión teórica y técnica acerca de si la computación cuántica debería basarse en un análogo programable de puertas lógicas digitales o en otra cosa completamente diferente. Los D-Wave, las únicas máquinas comercialmente disponibles que hoy por hoy pueden reclamar el derecho de usar efectos cuánticos en sus cómputos no usan puertas lógicas sino que implementan un algoritmo concreto conocido como temple cuántico el cual comentaremos más adelante.
No sé como explicar los algoritmos sin usar formalismos matemáticos propios de la mecánica cuántica. Por consiguiente, el lector alérgico a las ecuaciones posiblemente será mejor si deja el post aquí. Tampoco puedo explicar el archimencionado algoritmo de Shor que podría servir para romper la encriptación RSA y DSA sin explicar previamente la transformada cuántica de Fourier de la que depende.
La computación cuántica funciona aplicando una función que cambia un estado a través del tiempo. Esta función del tiempo se conoce como el Hamiltoniano (Ĥ) y lo que hace es evolucionar un estado inicial |ψ0⟩ a un estado final Û(t)|ψ0⟩ a través del operador unitario Û tal que dÛ/dt = iĤ(t)Û(t)/ħ.
Ĥ normalmente representa la energía total de un estado y es el programa a ejecutar en un computador cuántico.
Transformada cuántica de Fourier
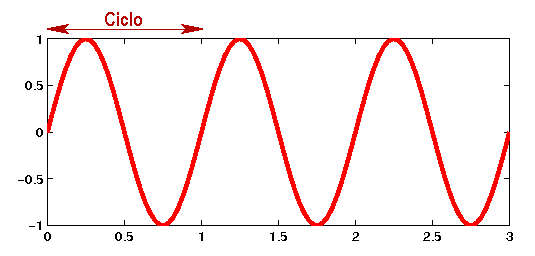
La transformada cuántica de Fourier es el análogo de la transformada discreta de Fourier de la cual daremos una definición constructiva. Se comienza con una función continua e integrable definida dentro de un intervalo de tiempo. Normalmente con forma de crestas y valles del estilo de una señal de audio o de radio como la de la siguiente gráfica.
Primero se hace un muestreo de los valores de la función a intervalos regulares de tiempo. En la gráfica 11 muestreos por segundo. En un intervalo de 3 segundos total N=33 muestreos. Estos muestreos expresan los valores de la función en función del tiempo. Para cada instante del tiempo conocemos el valor de la función.
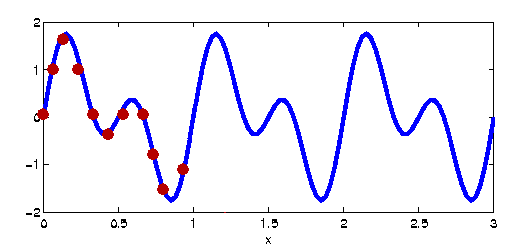
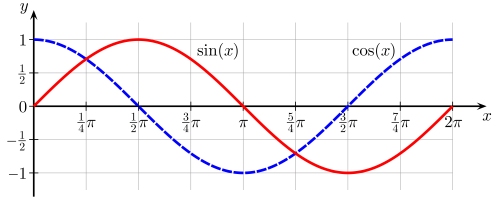
Ahora lo que deseamos hacer es expresar la función en el dominio de la frecuencia y no del tiempo. Es decir, deseamos expresar nuestra función como la suma de funciones sinusoidales de diferentes periodos. Lo cual se puede demostrar que es posible pero no abordaremos las razones de por qué. Para expresar en el dominio de la frecuencia nuestra función calcularemos la correlación entre ella y cada una de las funciones seno y coseno con una cantidad de ciclos desde 0 hasta N (el número de muestreos) durante el intervalo de tiempo en el que se aplica la transformación.
Si x0, x1, … xn son los valores de cada medida entonces la transformada discreta de Fourier es una serie de N números complejos X0, … Xn definido cada uno de ellos como
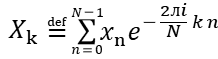
Teniendo en cuenta la fórmula de Euler según la cual
eix = cos(x) + i sen(x) y que sen(-x) = -sen(x)
cada término n-ésimo del sumatorio anterior se puede expresar también como
xn (cos(2πkn/N) – i sen(2πkn/N))
expresión en la que se aprecia explícitamente cómo se correlacionan los valores muestreados con los valores de las funciones coseno y seno.
La evaluación directa de la fórmula anterior requiere N² multiplicaciones y N(N-1) adiciones lo que computacionalmente equivale a una cota superior asintótica O(N²).
Si el tamaño de la muestra es una potencia de dos, se puede emplear un algoritmo llamado Transformada Rápida de Fourier que reduce la cota superior asintótica a O(N log N).
Hasta aquí la parte clásica de la transformada discreta de Fourier. Veamos ahora la versión cuántica. Lo primero de todo hay que tener en cuenta que la transformada cuántica de Fourier se aplica sobre todo un estado cuántico y no sobre los valores de sus medidas. En el caso cuántico la transformada toma como entrada un vector de amplitudes y produce como salida otro vector de amplitudes.
Dado el estado
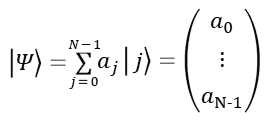
Su transformada quántica de Fourier se define cómo
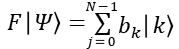
donde
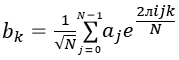
No se puede acelerar la transformada discreta de Fourier clásica mediante computación cuántica. Las razones son que no es posible establecer eficientemente una distribución inicial de amplitudes de probabilidad y que las amplitudes de probabilidad no son accesibles mediante medidas. Lo que podemos hacer es una medida sobre un estado y obtener |0⟩ o |1⟩ pero no es posible determinar mediante observación cual es la probabilidad de obtener |0⟩ o de obtener |1⟩ De modo que la transformada quántica de Fourier no es útil directamente sino sólo como parte de otros algoritmos que comentaremos más adelante.
Afortunadamente, existe una forma eficiente de obtener la transformada cuántica de Fourier mediante una combinación de puertas lógicas cuánticas llamadas puerta de Hadamard y puerta controlada de desplazamiento de fase. La puerta de Hadamard realiza la transformada discreta de Fourier sobre las amplitudes de probabilidad de un qubit. Para número de amplitudes que sea una potencia de dos N = 2n, la transformada cuántica de Fourier tiene una cota superior asintótica O (2n) la cual es exponencialmente más rápida que la transformada rápida de Fourier que es O(N log N) = O (2n log 2n) = O(2n n).
Estimación del periodo de una función
Supongamos que hay N dimensiones y un estado de la forma |Φ⟩ = Σ c|l+n r⟩ donde n=0…N/r-1 y |c| = √r/N. Esto se llama un estado periódico con periodo r y elemento compensatorio l. Al aplicar la transformada cuántica de Fourier a dicho estado se evolucionará a un nuevo estado |̃Φ⟩ = Σ αm|mN/r⟩ con m=0…r-1 y |αm|=√1/r para todo m. El nuevo estado también es periódico con elemento compensatorio cero cuya medida será un múltiplo de N/r. Esto se puede aprovechar para elaborar un algoritmo cuántico que encuentre el periodo basado en que si se aplica repetidamente la transformación se obtendrán resultados cuyo único factor cómún será el periodo.
Algoritmo de Shor
Algunos algoritmos criptográficos, y en particular RSA, se basan en la dificultad para encontrar los factores primos de un número entero grande (1024 bits o más). No se conoce ningún algoritmo capaz de factorizar un entero grande con una cota asintótica que sea polinómica respecto del tamaño del entero de entrada. El mejor algoritmo conocido para enteros grandes en la criba general del cuerpo de números cuya cota asintótica es exponencial.
El algoritmo de Shor lo que hace es descomponer la factorización de enteros en tres subproblemas: 1º) determinar si un número es primo o no, 2º) encontrar el mínimo común denominador y 3º) determinar el periodo de una función. Los dos primeros subproblemas se pueden resolver en tiempo polinómico con algoritmos clásicos y es en el tercero donde la transformada cuántica de Fourier marca la diferencia de complejidad asintótica utilizada en conjunción con el algoritmo clásico de expansión continua de fracciones.
El algoritmo de Shor no sirve para romper cualquier método criptográfico, sólo sirve para atacar los métodos basados en factorización de enteros como los sistemas clave pública. Los sistemas de cifrado simétrico o basados en funciones hash se consideran seguros frente a la computación cuántica.
Algoritmo de Grover
Lo que hace el algoritmo de Grover es equivalente a encontrar el valor de la variable x tal que para una función 𝑓 se verifique que 𝑓(x) = y. El algoritmo de Grover tiene una cota asintótica O(N½) y requiere O(log N) espacio adicional durante su ejecución. Intuitivamente, es equivalente a buscar a quien pertenece un número de teléfono en un listado ordenado por nombre. Sin un índice, la única forma de buscar es comprobar uno por uno el número de cada abonado lo cual requirirá en el peor caso tantas comprobaciones como abonados haya en el listado.
El problema insalvable del algoritmo de Grover, desde mi punto de vista, es que para que funcione hay que precargar toda la base de datos en qubits. Dado lo que cuesta actualmente cada qubit, es dudoso que tengamos un número de qubits suficiente para aplicaciones prácticas y, aunque lo tuviéramos, habría que precargar la base de datos entera desde un sistema externo, lo cual equivale a leerla entera con un recorrido por fuerza bruta de complejidad O(N).
El algoritmo de Grover tampoco se considera eficaz para atacar sistemas clave simétrica invulnerables al algoritmo de Shor, debido a que para aumentar el tiempo requerido por la desencriptación basta con duplicar el tamaño de la clave.
Algoritmo de temple cuántico
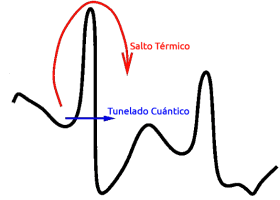 El algoritmo de temple cuántico, también llamado cristalización o en inglés quantum annealing, sirve para resolver problemas de optimización o de muestreo. El problema consiste en encontrar el mínimo de una función. La versión clásica de este algoritmo, conocida como temple simulado, lo que hace es provocar alteraciones térmicas en los estados para verificar si atraviesan una barrera de potencial. El temple cuántico puede aprovechar, además el efecto túnel para cruzar barreras de potencial. Por consiguiente, el temple cuántico proporcionará más aceleración cuando el perfil de la función esté compuesto por mínimos en valles separados por crestas altas y estrechas. Una analogía ingeniosa del temple cuántico puede visualizarse en este video.
El algoritmo de temple cuántico, también llamado cristalización o en inglés quantum annealing, sirve para resolver problemas de optimización o de muestreo. El problema consiste en encontrar el mínimo de una función. La versión clásica de este algoritmo, conocida como temple simulado, lo que hace es provocar alteraciones térmicas en los estados para verificar si atraviesan una barrera de potencial. El temple cuántico puede aprovechar, además el efecto túnel para cruzar barreras de potencial. Por consiguiente, el temple cuántico proporcionará más aceleración cuando el perfil de la función esté compuesto por mínimos en valles separados por crestas altas y estrechas. Una analogía ingeniosa del temple cuántico puede visualizarse en este video.
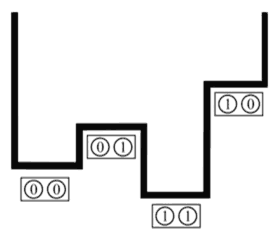 Veamos ahora cómo ejecuta este algoritmo el D-Wave sobre el retículo de grupos de 8 qubits acoplados que hemos presentado anteriormente. El muestreo de la función es discreto. Supongamos que tenemos dos qubits. Entonces podemos representar 4 estados. La energía para cada estado se introduce en el bias. Lo que hace el algoritmo es buscar el mínimo de la función definida por los valores de energía. El último modelo de D-Wave tiene 1.000 qubits y, por consiguiente, puede trabajar con 21000 estados.
Veamos ahora cómo ejecuta este algoritmo el D-Wave sobre el retículo de grupos de 8 qubits acoplados que hemos presentado anteriormente. El muestreo de la función es discreto. Supongamos que tenemos dos qubits. Entonces podemos representar 4 estados. La energía para cada estado se introduce en el bias. Lo que hace el algoritmo es buscar el mínimo de la función definida por los valores de energía. El último modelo de D-Wave tiene 1.000 qubits y, por consiguiente, puede trabajar con 21000 estados.
El algoritmo de temple cuántico hace uso de los principios de computación cuántica adiabática. En el D-Wave se define un Hamiltoniano de Ising que se compone de dos partes: una para inicializar el estado y otra que representa el problema a resolver.
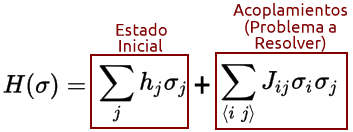
Por el teorema adiabático, el sistema representado por el Hamiltoniano de Ising evolucionará desde el estado representado por el primer término hasta el estado de mínima energía del segundo término, que es la solución al problema.
Actualizaciones:
D-Wave upgrade: How scientists are using the world’s most controversial quantum computer (Elizabeth Gibney)
Los ordenadores cuánticos están listos para salir del laboratorio en 2017 (Davide Castelvecchi)

 Recientemente encontré compartido en Facebook un artículo de The Economist titulado The alphabet of success sobre las guerras por el talento. Para ilustrarlo los editores han seleccionado una fotografía alegórica de un mando intermedio mitad ejecutivo hipster mitad caballero medieval. No sé si la imagen simboliza algún tipo de admiración idealizada por los guerreros de antaño o si la han colocado con doble intención (lo más probable). Pero en cualquier caso me ha servido para recordar que organizativamente seguimos en la edad media.
Recientemente encontré compartido en Facebook un artículo de The Economist titulado The alphabet of success sobre las guerras por el talento. Para ilustrarlo los editores han seleccionado una fotografía alegórica de un mando intermedio mitad ejecutivo hipster mitad caballero medieval. No sé si la imagen simboliza algún tipo de admiración idealizada por los guerreros de antaño o si la han colocado con doble intención (lo más probable). Pero en cualquier caso me ha servido para recordar que organizativamente seguimos en la edad media.




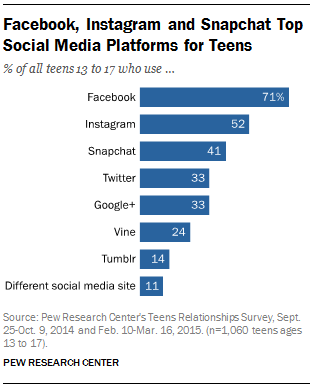
 Existen no pocos padres preocupados por las relaciones de sus hijos a través de las redes sociales. Frente a mi casa hay un bonito parque con varios rincones secretos encantadores. Bueno, secretos excepto cuando miras desde mi ventana en un tercer piso. Entonces puedes ver a los adolescentes allí haciendo todas las cosas que sus padres no quieren que hagan. Existen
Existen no pocos padres preocupados por las relaciones de sus hijos a través de las redes sociales. Frente a mi casa hay un bonito parque con varios rincones secretos encantadores. Bueno, secretos excepto cuando miras desde mi ventana en un tercer piso. Entonces puedes ver a los adolescentes allí haciendo todas las cosas que sus padres no quieren que hagan. Existen