
Los desarrolladores suelen catalogarse en dos grandes grupos: imperativos y funcionales. Y dentro de cada grupo, front-end o back-end. Existen luego especialidades: los que hacen programación concurrente con actores, los especializados en algoritmos de programación dinámica, los científicos de datos, etc. La gestión de procesos de negocio, o Business Process Management (BPM) en inglés, se concibe usualmente como un conjunto de herramientas, pero técnicamente se trata más bien de otro paradigma al mismo nivel que la programación orientada a objetos. En este post explicaré principalmente desde el punto de vista del desarrollador en qué consiste BPM y cuales son las herramientas más populares disponibles en el mercado.
BPM
Al BPM lo empezamos llamando Workflow allá por los noventa, luego los fabricantes fueron evolucionando hacia estándares de OMG y OASIS que veremos más adelante y le cambiaron la denominación por motivos comerciales. La piedra angular de BPM es la definición de lo que es un proceso de negocio. En esencia, es sencillo: un proceso de negocio toma unas entradas, que son objetos de negocio, y produce unas salidas, otros objetos de negocio. Por el camino, realiza una serie de actividades con las entradas y toda decisiones sobre qué actividades realizar a continuación en función de cómo van siendo modificadas las entradas o en respuesta a eventos externos. El proceso también puede mantener algunas variables internas de estado que no son visibles externamente. Y la salida puede enviarse a un sistema externo normalmente a través de un servicio web.
El BPM maneja sus propios objetos de negocio los cuales, en general, son diferentes de las entidades que se almacenan en el modelo relacional subyacente a los datos empresariales. Por consiguiente, se requiere alguna forma de mapeo entre los objetos del BPM y las entidades relacionales de larga vida.
Los objetos de negocio del BPM se parecen mucho a las estructuras de datos en C. Es decir, son clases que tienen propiedades pero no métodos. Esto es debido a que en BPM es responsabilidad de la actividad modificar el estado de los objetos que maneja. No obstante, en algunas herramientas, los objetos de negocio se pueden representar como clases Java y la actividad puede delegar el comportamiento en métodos de la clase. Pero una diferencia clave entre la programación orientada a objeto y la programación orientada a procesos es que en esta última es la actividad quien controla los cambios en el estado interno de los objetos de negocio. Los objetos de negocio sobreviven sólo en tanto en cuanto el proceso al que pertenecen siga abierto, y deben persistirse explícitamente a la base de datos en el caso de que deban ser preservados tras la finalización del proceso. Los procesos se pueden organizar en carriles para identificar las diferentes etapas del proceso y asignar roles de usuario a cada una de ellas. Finalmente, los procesos se almacenan en aplicaciones que se despliegan a un servidor. En resumen, de más alto a más bajo nivel tenemos:
— Servidores de aplicaciones.
— Aplicaciones de proceso.
— Carriles.
— Procesos.
— Subprocesos.
— Actividades.
— Reglas de decisión.
— Eventos.
— Objetos de negocio de entrada.
— Objetos de negocio de salida.
El estándar de OMG para especificar todo esto es BPMN. Se trata de un esquema XML que casi todas las herramientas pueden leer y representar en pantalla mediante una notación gráfica bien definida. Por ejemplo, he aquí una captura del BPM de IBM que es el que tengo en local. Muestra tres carriles: Analisys, System y Vendor y seis actividades.
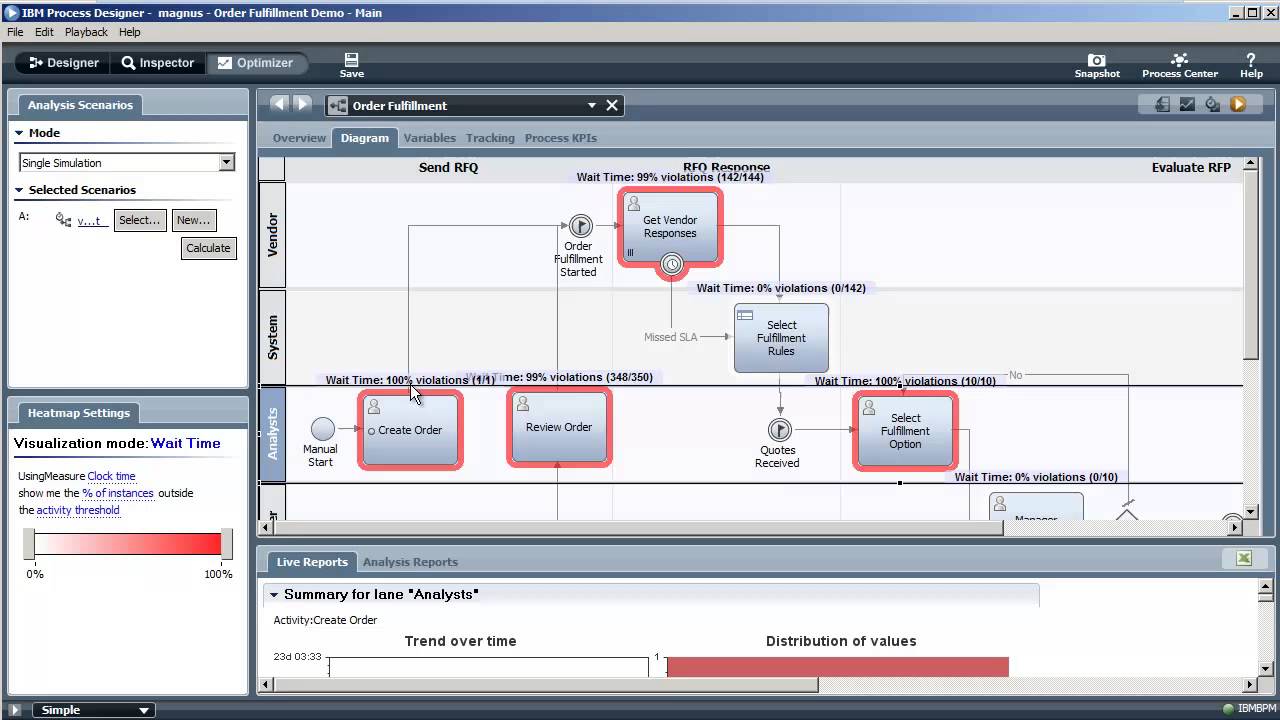
Nunca se trabaja directamente con BPMN, las herramientas permiten pinchar y arrastrar los componentes del proceso para componerlo visualmente. De hecho, se supone que esa es una de las ventajas de BPM, que los usuarios y los programadores pueden compartir una visión de los procesos de negocio. Sin embargo, la mayoría de las herramientas no están pensadas para que los usuarios diseñen nada. IBM enfocó este problema ofreciendo una herramienta web específica sólo de modelización Blueworks Live. Microsoft Visio también puede crear diagramas exportables a BPMN. La ventaja de Blueworks es que al tratarse de una herramienta web permite a usuarios remotos colaborar en la creación y revisión de un proceso.
Alternativamente, o complementariamente, es posible definir los procesos en BPEL, sucesor del WSFL de IBM y XLANG de Microsoft mantenido por OASIS. BPEL nació como un vehículo para la orquestación de procesos mediante servicios web descritos mediante WSDL. La ventaja de BPEL frente a BPNM es que está más próximo a lo que una máquina puede ejecutar realmente. Sin embargo, a diferencia de OMG con BPMN, OASIS no proporciona una notación gráfica estándar para BPEL e internamente el XML de BPEL es más complejo que el de BPMN. No obstante, prácticamente todos los grandes fabricantes: IBM, Oracle, SAP, Microsoft, Red Hat, etc. Dan soporte tanto a BPEL como a BPMN.
En la práctica y en mi propia experiencia, las arquitecturas SOA descritas en BPEL presentan inconvenientes:
1º) Cuando cada servicio es responsabilidad de un equipo independiente resulta complicado coordinarlos entre ellos para que no se bloqueen unos a otros.
2º) Debido a que los subsistemas se comunican por HTTP, los tiempos de latencia son difíciles de estimar ya que dependen de la electrónica de red con la consecuencia de que el funcionamiento del sistema en conjunto fácilmente puede llegar a ser lento e impredecible.
3º) Debe existir algún convenio para garantizar la compatibilidad de versiones entre el cliente y el servidor de cada servicio.
4º) Es complicado crear y ejecutar sistemáticamente pruebas unitarias. Aunque los procesos se pueden simular, las herramientas no proporcionan en general un buen marco de trabajo TDD e integración contínua.
Mi acercamiento personal es que lo mejor suele ser modelizar primero los procesos en BPMN sin definir explícitamente los de detalles de las interacciones entre los servicios. Luego encapsular las llamadas a cada servicio en subprocesos BPEL. Esto puede diferir de las mejores prácticas recomendadas por el fabricante, como en el caso de Oracle, ya que sus herramientas presumen de soportar BPMN o BPEL indistintamente, y, por consiguiente, no es preciso trazar una línea divisoria clara entre el uso que se le da a cada uno de ellos.
DMN
Complementario y relacionado con BPM se encuentra DMN Decision Model and Notation. DMN es una notación específica para representar reglas de negocio. BPM se relaciona con DMN a través de una actividad denominada Business Rule Task. Es decir, existe un punto en el proceso de negocio en el cual se ejecuta una regla DMN que sirve para tomar una decisión sobre por dónde debe continuar el proceso. La motivación principal para DMN es externalizar las reglas de negocio y permitir que los usuarios puedan modificarlas para adaptar el funcionamiento de proceso a los requerimientos cambiantes del entorno. Además de DMN, que es un estándar relativamente nuevo de OMG, existen varios lenguajes específicos de domino o Domain Specific Language (DSL) en inglés. Estos lenguajes tratan de proporcionar una representación de las reglas que los usuarios puedan leer en lenguaje natural y modificar de forma segura con un asistente. Antaño, IBM mantenía su propio estándar BRML, aunque lo descontinuó en favor de DMN.
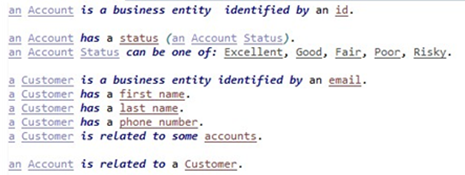
La pega fundamental de los DSL para reglas de negocio es que existe un peaje de entrada a pagar tanto en la complejidad de la aplicación que los maneja como en la curva de aprendizaje del lenguaje. Por ejemplo, el siguiente DSL y regla de negocio estan tomados de IBM ODM (Operational Decision Manager).

Herramientas
Debido a que la necesidad de automatizar procesos de negocio es importante, los grandes fabricantes de software llevan ya bastante tiempo invirtiendo en el desarrollo de herramientas de gestión de procesos y reglas de negocio. Las herramientas de BPM, en general, no son sencillas. Los fabricantes se lanzaron a la carrera de añadir más y más funcionalidades para puntuar mejor en los rankings comparativos. Además los peces grandes se fueron comiendo a los pequeños. Como resultado, las herramientas resultan con frecuencia complejas y bastante pesadas. Usarlas no es nada trivial (hasta que se aprende cómo hacerlo). Además no siempre se pueden poner los procesos bajo un sistema de control de versiones estándar como SVN o Git y los despliegues al servidor de aplicaciones también siguen un procedimiento exclusivo de cada herramienta.
Los proyectos de BPM pueden reportar grandes beneficios operativos pero con frecuencia son caros y difíciles de poner en práctica, ya que requieren de una costosa coordinación interdepartamental, integraciones de datos complicadas y procesos de cambio mental y organizacional que pueden tardar toda la vida.
Los principales proveedores de software BPM privativo son PEGA Systems, IBM, Oracle y Appian. En el mercado español también es significativo AuraPortal. Y las opciones Open Source más comunes son BonitaSoft, Alfresco Activiti, Drools, OpenRules y jBPM de Red Hat quien también compró Polymita, otro proveedor español, en 2012. Por otro lado, los usuarios de SAP también pueden contar con herramientas que no son para nada una mala opción, aunque tanto IBM como Oracle han invertido bastante en la intergración de sus respectivos BPM con SAP.
Las herramientas se pueden comparar en función de su puntuación en los siguientes criterios:
— Modelización de procesos.
— Definición y ejecución de reglas de negocio.
— Diseño de pantallas.
— Interfaces con sistemas externos.
— Simulación de procesos.
— Analíticas de rendimiento.
— Despliegue y gestión de la configuración.
— Administración diaria del sistema en producción.
Los proveedores de las herramientas más potentes ponen énfasis en que no sólo se trata de descubrir, modelizar e implentar procesos, sino también de medir su eficiencia y buscar puntos calientes a mejorar. En la práctica, la simulación y la optimización se usan casi siempre menos de lo previsto, ya que bastante tiene el cliente con sobrevivir al proceso de transformación organizacional como para ponerse a optimizarlo antes de tenerlo ni siquiera funcionando.
El diseño de pantallas es otro punto caliente. Yo personalmente aún no he encontrado ningún diseñador de pantallas integrado que me convenza. Los diseñadores de pantalla integrados que conozco carecen de funcionalidades nativas para evitar el cross-site scripting, la inyección de SQL y otras modalidades de ataque. Por todo esto, mi opinión personal es que lo mejor es diseñar las pantallas con un framework MVC y conectarlo al BPM mediante un bus de integración de datos.
SaaS
El BPM en modo de software como servicio merece una mención aparte. Appian, IBM, Oracle, Bonita y muchos otros fabricantes que no he podido evaluar ofrecen soluciones de BPM en la nube. Hasta donde yo conozco, el escollo intrínseco de estas plataformas es que son externas a los sistemas de la casa. Un BPM tiene que integrarse casi siempre al menos con otros tres tipos de sistemas: una base de datos relacional, un gestor documental y varios ERPs y CRMs. Si el BPM está en la nube al final tiene que cruzar toda la Internet cada vez que se ejecuta alguna actividad, lo cual es tanto un problema de rendimiento como de seguridad. No obstante, el BPM en cloud puede ser una opción muy viable para empezar con un proyecto táctico experimental más rápido y barato de lo que costaría desplegar un cluster de BPM on-premise; o cuando se requiere de una solución de BPM en una organización geográficamente distribuida.
Conclusiones
Aunque las herramientas de BPM han mejorado, y siguen mejorando bastante, el diseño e implementación de una solución BPM sigue presentando importantes desafíos.
Desde el punto de vista del desarrollador requiere un cambio de mentalidad en el diseño técnico y en la gestión de la configuración, acostumbrándose a sacar partido de las herramientas de programación visual, de las funcionalidades para el despliege de aplicaciones de proceso, y superando el desafío de combinar la integración contínua y el control de versiones con ramas con ciclo de vida de un proceso en desarrollo, pruebas y producción.
Desde el punto de vista del usuario, requiere aprender a utilizar nuevas herramientas y colaborar de forma más estrecha con los desarrolladores en la definición de los procesos .
Desde el punto de vista del gerente, requiere reunir una gran cantidad de apoyo directivo y organizacional y descubrir los KPIs y puntos de mejora en un conjunto de procesos que puede proliferar rápidamente hasta hacerse difícilmente manejable sin una buena metodología de gestión de cambios.
Post relacionado: Introducción a Domain Driven Design.





