
Hace ya tres décadas que se comprobó empíricamente que los equipos pequeños de desarrollo de software tienden a ser más eficientes que los grandes. «Pequeño» en este contexto es un grupo de 3 a 10 personas. Desde entonces, han ido apareciendo diversas metodologías enfocadas sobre todo en explotar estas eficiencias que generan los equipos compactos como Scrum (1986) y XP (1996). Cuando se habla de Agile casi todo el mundo se refiere a Scrum. En este post voy a comentar una parte de los fenómenos que se producen cuando hay más de un equipo trabajando en una cadena de desarrollo de software, particularmente aplicando Kanban y sus fundamentos sobre la Teoría de Restricciones (TOC) de Goldratt.
Kanban instantáneo
Para quien se aburra con los post largos, lo voy a resumir en dos imágenes. La idea esencial es que la velocidad de pico de un sistema está limitada a la velocidad de su cuello de botella más estrecho en cualquiera de la etapas. Entonces, lo primero de todo que hay que hacer es identificar los cuellos de botella. Para no atascarse en los cuellos de botella hay que seguir dos principios: 1º) los recursos de un cuello de botella nunca deben de estar ociosos porque el coste de parada del cuello de botella es como si se parase todo el sistema y 2º) hay reducir al mínimo la cantidad de funcionalidades que están a la espera de ser procesadas en una determinada etapa, esto es lo que la TOC llama Work In Process (WIP) aunque a mi no me gusta el término aplicado al software porque da entender que no deberían haber muchas funcionalidades en desarrollo lo cual no es cierto, lo que no tiene que haber es ninguna funcionalidad a medio desarrollar porque se está esperando a que alguien de la siguiente etapa del proceso quede libre para ponerse con ella. Este control puede llevarse a cabo de forma extraordinariamente sencilla con una pizarra que es la piedra angular de Kanban.
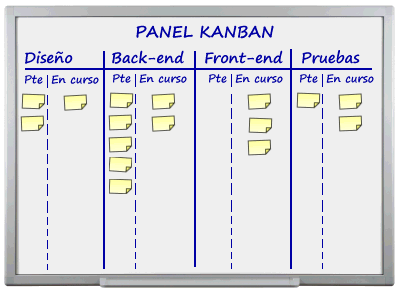
Los cuellos de botella en desarrollo de software pueden ser de tres tipos: 1º) limitaciones reales impuestas por los recursos disponibles y las dependencias entre ellos; 2º) cuellos de botella creados artificialmente como efecto secundario de las políticas de la compañía, en general, tras la resolución de cada problema en una empresa aparece un iluminado que inventa un procedimiento burocrático para evitar que dicho problema vuelva a suceder, con el paso del tiempo la burocracia se intensifica y no sólo consume tiempo de los trabajadores sino que, además, dificulta a menudo los cambios productivos necesarios para eliminar cuellos de botella; 3º) cuellos de botella derivados del desdén por los principios metodológicos, por ejemplo no hablar lo suficiente cara a cara con el cliente, induce a errores y malentendidos que alimentan toda la cadena con especificaciones basura, o saltarse el principio de la simplicidad puede inducir a crear componentes elefánticos que atascan todo el sistema porque resultan carísimos de desarrollar y de mantener.
Además del Kanban Board, resulta muy conveniente tener otra pizarra con una matriz de asignación de funcionalidades a individuos en la cual, idealmente, ningún individuo debería estar trabajando en más de una funcionalidad simultáneamente.
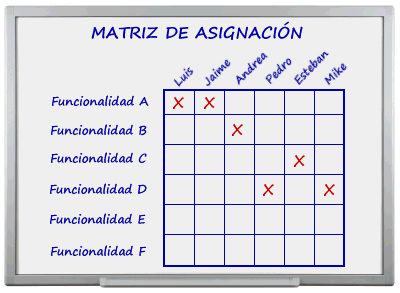
No es factible en la práctica que cada programador esté trabajando exclusivamente en una funcionalidad. Podría ser que el desarrollo de dicha funcionalidad dependa de la disponibilidad de una base de datos que está caída, entonces sería bueno que el desarrollador pudiera ocuparse momentáneamente de la siguiente funcionalidad en su lista de prioridades. Por otra parte el programador tiene otras tareas como el mantenimiento correctivo. Una posible solución a la interferencia entre el desarrollo de nuevas funcionalidades y la corrección de defectos software es separar a los programadores en dos grupos: desarrollo y bug fixing, rotando a la gente entre ambos grupos, incluído el personal senior, ya que el corregir un defecto de diseño puede implicar refactorizar una buena cantidad de código para lo cual probablemente se requiera un programador con experiencia.
Las tres variables de la Teoría de Restricciones
Hasta aquí el resumen ejecutivo. Ahora vamos a examinar un poco más en los detalles de cómo se puede aplicar la Teoría de Restricciones al desarrollo de software. Aunque previamente conviene señalar que la TOC es una metodología de organización del trabajo originariamente ideada para fábricas. Antes de extrapolar sus principios al desarrollo de software hay que tener en cuenta que las funcionalidades son intangibles físicos, en una fábrica mantener piezas en stock o productos terminados pendientes de entregar al cliente es carísimo, mientras que en programación el coste de almacenar una funcionalidad a medio hacer es ridículamente bajo, por consiguiente, una parte del tremendo énfasis que pone la TOC en que haya el mínimo número de piezas pululando por la fábrica en cada momento no es tan importante realmente para el desarrollo de software. Pero incluso teniendo en cuenta lo barato que es «almacenar» intangibles en relación a un stock físico, han aparecido metodologías ágiles como Lean que se centran en reducir el inventario y producir la mínima cantidad de desperdicios. Entremos en materia de la motivación para ello.
La TOC se basa en maximizar el throughput (T). Lo que la TOC define como throughput es la facturación menos todos los costes variables.
Throughput = Facturación – ∑ Costes Variables
En los libros de Goldratt a los costes variables se les llama también inventario, entendido como todo el dinero que el sistema ha invertido en adquirir cosas que luego pretende vender, principalmente materias primas en el caso de una fábrica, en el caso de software el empaquetado, la instalación, formación, soporte, etc.
El throughput está relacionado con el beneficio neto de mediante la fórmula:
Beneficio Neto = Throughput – ∑ Costes Fijos de Operación
Los gastos de operación son todo el dinero que gasta el sistema para convertir el inventario en ingresos netos. Probablemente una de los mayores avances en la reducción de los costes de operación haya sido el Software Libre.
En la TOC «clásica» la mano de obra no se considera como un coste variable (excepto las horas extra si las hubiere). La I+D, en principio, es un gasto de operación. Si la empresa va a vender ese know-how, como en el caso de una patente, entonces se puede considerar inventario. Pero si el know-how es sólo una parte necesaria de la fabricación del producto entonces será gasto de operación. Yo personalmente creo que, en lo referente al software, la mano de obra sería mejor considerarla un coste variable y no un coste fijo ya que, en general, siempre se necesita más mano de obra para producir más software, al contrario de lo que sucede en una fábrica con exceso de capacidad donde el mismo número de operarios pueden casi siempre producir más piezas de las que realmente están produciendo por unidad de tiempo.
El último parámetro que mide TOC es el Retorno de Inversión (ROI) que mide la eficacia con la que el dinero invertido inicialmente en la empresa está generando más dinero.
Retorno de Inversión = Beneficio Neto / Inversión
El objetivo de las metodologías ágiles también es maximizar el throughput, pero es un throughput de naturaleza ligeramente diferente al que define la TOC. El throughput de Agile se mide por la cantidad de funcionalidades (valor) entregado al cliente por unidad de tiempo mientras que para la TOC el throughput es una métrica basada en el ingreso monetario que generan los productos entregados, medido en tres dimensiones: ingresos brutos, liquidez y rentabilidad de la inversión. Es tentador definir el throughput en términos de los elementos que manejan las distintas metodologías de desarrollo.
• Un ítem del backlog en Scrum.
• Un story point en eXtreme Programming.
• Una feature en Feature-Driven Development.
• Un punto función en la metodología Waterfall.
Pero es importante recalcar que debe usarse algún método para relacionar las métricas de producción de código con los ingresos que genera dicho nuevo código. De lo contrario todos los gastos fijos y variables sólo sirven para crear un producto ruinoso destinado a criar malvas sin generar ningún beneficio para la compañía. Por ejemplo, es posible definir story points que generan ingresos fijos como sugiere Cohn. Entonces maximizar el throughput efectivamente lo mismo que maximizar la cantidad de story points entregados por unidad de tiempo. Pero esa no es la única forma de maximizar el throughput porque hay funcionalidades muy costosas de desarrollar que sin embargo son muy difíciles de monetizar mientras que que otras que son más de nicho resultan ser muchísimo más lucrativas. Por consiguiente también se puede aumentar el throughput desarrollando funcionalidades para nichos que están dispuestos a pagar mucho por ellas («menos es más»).
Los cinco pasos para adecuar el flujo a la demanda
Para maximizar el beneficio, la liquidez y el retorno de inversión, la TOC propone focalizarse por completo en cinco pasos:
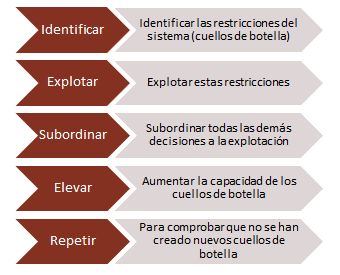
Antes de que popularizase el uso de la TOC y el Just In Time radical de López de Arriortua, las fábricas optimizaban su producción basándose en contabilidad analítica (CA) y otros controles de métodos y tiempos que datan de la época en la que Alfred P. Sloan levantó el imperio de la General Motors. La contabilidad analítica es esencialmente una metodología de optimización local que busca medir y mejorar la eficiencia de cada etapa de un proceso. Por el contrario a la TOC no le preocupan los óptimos locales. Es una teoría de optimización global que trata de equilibrar el flujo de salida de productos terminados con la demanda del mercado. No se trata de ajustar la capacidad de la factoría a la del mercado, porque, de hecho, en la TOC hay un teorema que demuestra que cuando se ajusta la capacidad a la demanda del mercado, los ingresos descienden y los inventarios se disparan. Tal demostración está basada en dos fenómenos que se producen en todas las factorías: las tareas dependientes y las fluctuaciones estadísticas.
Tareas dependientes y fluctuaciones estadísticas
Se dice que una tarea depende de otra cuando no se puede empezar hasta que no se ha completado la anterior (esto es muy obvio para cualquiera que haya hecho un simple Gantt alguna vez).
Las fluctuaciones estadísticas se producen cuando el tiempo necesario para completar una tarea varía entre una ejecución y la siguiente.
Cuando hay tareas dependientes y fluctuaciones estadísticas no se puede medir la capacidad de un equipo sin relacionarla con otros equipos en la cadena de producción. Según un principio matemático, en una dependencia lineal de dos o más variables, las fluctuaciones de las variables posteriores oscilan alrededor de la desviación máxima
producida en las variables precedentes. Es decir, la máxima desviación en una tarea será el punto de partida de la tarea siguiente.
Como corolario de la covariancia entre capacidades productivas de cada etapa resulta que una cadena de producción donde todas sus etapas funcionan de forma eficientemente óptima no es una cadena óptima en su conjunto. De hecho, es una cadena muy ineficiente. La utilización inteligente de los recursos se produce cuando estos están contribuyendo a a aumentar el throughput. Si los recursos simplemente están activados produciendo funcionalidades que los cuellos de botella no pueden procesar entonces sólo se está malgastando dinero en hacer crecer el WIP inútilmente.
No obstante lo anterior, la eficiencia en cada etapa también importa. Por ejemplo, en desarrollo de software es sabido que cada etapa debe pasar el mínimo de funcionalidades defectuosas a la siguiente pues el coste de corrección de los bugs aumenta exponencialmente a medida que se demora su detección y eliminación en el tiempo. Además, las funcionalidades defectuosas tienen un efecto particular en el software. Cuando se producen piezas defectuosas en una cadena de montaje lo que sucede es que los recursos cuello de botella trabajan procesando piezas que, a la postre, no pasarán el control de calidad. Pero en el software es aún peor porque un cambio en los interfaces de un componente de back-end puede obligar a cambiar una buena parte del código del front-end, y eso es muy mal asunto si el front-end resulta ser un cuello de botella.
Una mención especial merece, en mi opinión, el peligro del Test Driven Design. Aplicada de forma estricta, esta metodología requiere que primero se escriban los test que ha de pasar el software, luego se escriba la mínima cantidad posible de código para pasar los test y, si aparecen nuevos requerimientos, entonces se vaya refactorizando el código original para acomodarlos. Esto es fantástico cuando sólo hay que desarrollar un programa que se comporte de una manera muy específica. Pero también es la forma perfecta de volver loco a un desarrollador de front-end refactorizándole el código de back-end cada dos por tres. Cuando pasa eso los desarrolladores de front-end tienen que estar a diario pendientes de la versión exacta de las librerías que utilizan, se produce una considerable cantidad de retrabajo y los miembros del equipo de usuarios internos de los APIs de back-end acaban más quemados que la pipa de un indio. O, más llanamente, es una mala idea convertir a los desarrolladores de front-end en los beta testers de los diseños del back-end.
El efecto de los cambios en la capacidad sobre el throughput
La “contabilidad del throughput para ingeniería” (TAE) tiene tres aspectos especialmente interesantes en lo referente a cómo cambia el throughput cuando se cambia la capacidad de una etapa local.
1º) Cuando se despide un programador se mide no sólo el coste de reemplazarle, sino también cuánto afecta su marcha al throughput que puede ser un coste mucho mayor si resulta que trabajaba en un cuello de botella.
2º) Cuando se contrata a alguien nuevo el throughput no cambia a menos que sea asignado a un cuello de botella. Cuando se subcontrata bajan los costes fijos y suben los variables pero también es probable que cambien los cuellos de botella. Por consiguiente, puede darse el caso de que la subcontratación reduzca el throughput.
3º) Cuando los proyectos están restringidos en plazo, presupuesto y recursos, cada cuello de botella necesita un buffer pero los buffers incrementan los costes de operación sin incrementar el throughput. No hay que poner buffers por tarea. Lo que hay que hacer es poner un buffer global para todas las tareas que requiere el desarrollo de una funcionalidad y monitorizar cómo de rápido se está consumiendo a medida que avanzan las etapas.
Monitorización de la productividad
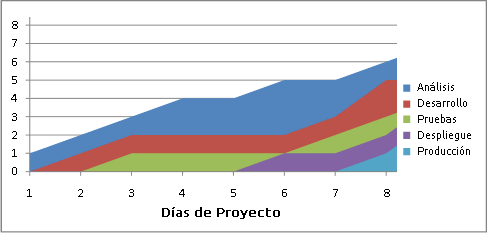
Para llevar un seguimiento de la productividad a menudo se usan diagramas de flujo acumulativo. En un sistema ideal donde se pide una funcionalidad cada día y se tardan 5 días en ponerla en producción un diagrama de flujo acumulativo tendría el siguiente aspecto:
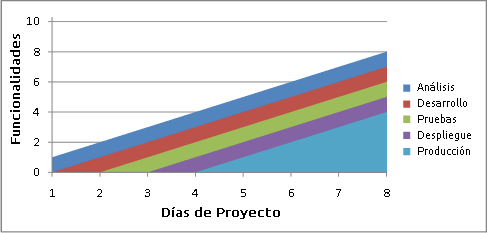
Aunque un diagrama real se parecerá bastante más a este otro:
Para saber más: Agile Management for Software Engineering: Applying the Theory of Constraints for Business Results (David J. Anderson)





Pingback: Por qué hay que enseñar a los niños a programar (entre otras cosas) | La Pastilla Roja
Pingback: Muerte por agilismo | La Pastilla Roja
Pingback: Cómo sobrevivir a las estimaciones de software | La Pastilla Roja
Pingback: Resumen Lean Software Development | Samuel Casanova