 Supongo que a estas alturas, todos sabemos, o como mínimo sospechamos, que los anunciantes saben quiénes somos, dónde vivimos, si tendremos un hijo en los próximos tres meses, dónde nos fuimos de vacaciones el mes pasado, qué marca de ropa interior usamos o si estamos teniendo problemas de salud. En este artículo repaso lo que se sabe acerca de cómo averiguan todo esto y qué se puede hacer para limitar la información que se proporciona a empresas interesadas en saber acerca de nosotros, ya sean proveedores de productos de consumo, bancos, aseguradoras o agencias del gobierno.
Supongo que a estas alturas, todos sabemos, o como mínimo sospechamos, que los anunciantes saben quiénes somos, dónde vivimos, si tendremos un hijo en los próximos tres meses, dónde nos fuimos de vacaciones el mes pasado, qué marca de ropa interior usamos o si estamos teniendo problemas de salud. En este artículo repaso lo que se sabe acerca de cómo averiguan todo esto y qué se puede hacer para limitar la información que se proporciona a empresas interesadas en saber acerca de nosotros, ya sean proveedores de productos de consumo, bancos, aseguradoras o agencias del gobierno.
Debido a su desconocimiento de los entresijos, los usuarios están en desventaja respecto de los anunciantes. Por cuestiones de conveniencia para los anunciantes y debido a su lobby, la protección normativa frente a los daños que puede causar el uso abusivo de datos ha sido reemplazada por un «consentimiento informado», excepto que no es posible tal cosa como que el usuario entienda bien a qué está dando su consentimiento cuando cede sus datos a una de las empresas voraces de información comercial.
Quería escribir sobre las técnicas estadísticas que usan los anunciantes, pero haciéndolo me di cuenta de que no se pueden entender sin conocer cómo se recopilan los datos en que se basan. De modo que me ha quedado un prólogo bastante largo para un texto estructurado en 3 partes:
1ª) Cómo se identifica y se sigue a los consumidores online y offline.
2ª) Qué se puede hacer para protegerse contra el seguimiento.
3ª) Los fundamentos estadísticos de la publicidad contextual.
Como es habitual en La Pastilla Roja, el texto va de lo menos técnico a lo más técnico para que cada cual pueda leer hasta donde quiera. Por cuestión de espacio, me he dejado en el tintero las herramientas para anunciantes que quizá sean el tema de una segunda parte de éste artículo.
1. Cómo se identifica y se sigue a los consumidores
En los primeros tiempos de la Web 1.0 lo que se usaba para recopilar estadísticas de uso eran los logs del servidor web. Los logs no requerían instrumertar las páginas web visitadas y no en vano Google compró Urchin en 2005 justo cuando Urchin acababa de lanzar su versión SaaS.
Hoy en día, no obstante, existen decenas de métodos diferentes mediante los cuales los anunciantes identifican, etiquetan y siguen a los internautas. Casi siempre estos métodos se usan de forma combinada para enriquecer la información disponible de cada persona.
Podemos enumerar entre los principales:
- Cookies
- Super Cookies
- Identificadores de dispositivo móvil
- Beacons
- Audio Beacons
- Almacenamiento local HTML 5
- Geolocalización y redes WiFi
- Fingerprinting
- Metadatos JPEG
- Adobe Flash, Applets Java y controles ActiveX
- Plug-ins, toolbars y spyware
- Etags
- Información recopilada por Google
- Whatsapp y Facebook
- Telemetría de Windows 10
- Inspección profunda de paquetes
- Información obtenida fuera de Internet
- Brechas de seguridad
Cookies
Las cookies son el medio más antiguo y todavía el más usado para seguir a los usuarios. Una cookie es ni más ni menos que un fichero de texto que un sitio web graba en el disco del ordenador del usuario. Las cookies, en principio, sirven a un propósito bienintencionado. El protocolo de comunicación HTTP que usan las páginas web es «sin estados». Esto significa que entre una petición y la siguiente el servidor no tiene, a priori, ninguna forma de saber si el ordenador y el usuario que realizaron la segunda petición son los mismos que realizaron la primera. El inconveniente de este comportamiento es que en muchas ocasiones hace falta mantener vinculadas un serie de peticiones, por ejemplo, para mantener vivo un carrito de la compra. El navegador web puede, entonces, ir guardando los artículos seleccionados en una cookie y enviarla al servidor para completar el proceso de compra. Las cookies ordinarias sólo son accesibles para el dominio que las creó. Es decir, si amazon.com crea una cookie entonces esa cookie sólo podrá ser leída por Amazon. Además, las cookies se envían de nuevo en cada petición HTTP.
Super Cookies
Un tipo de cookie prácticamente desconocida es la super cookie HSTS. Resulta que los navegadores web modernos tienen una funcionalidad llamada HTTP Strict Transport Security (HSTS). Esta funcionalidad sirve para indicar que un sitio web debe ser accedido sólo a través de HTTPS. El servidor puede redireccionar de HTTP a HTTPS. El problema es que si esto se hace en cada petición entonces hay que redireccionar cada vez que el cliente pide una nueva página al mismo servidor y esto es un proceso lento. Entonces lo que hace el servidor es indicarle al cliente que después de la primera, todas las peticiones que se sigan deberán ser por HTTPS aunque el cliente haya escrito http:// en la barra de direcciones. Para lograr esto, el servidor coloca una supercookie en el cliente que contiene un identificador único y que no se puede ver ni borrar desde el interfaz de usuario. El identificador único de HSTS puede entonces ser usado por el servidor para saber si está viendo al mismo cliente por segunda vez.
Identificadores de dispositivo móvil
Las apps de los móviles no soportan cookies, pero tienen un identificador único de dispositivo que se envía al servidor y pueden realizar almacenamiento local. Por ejemplo, iOS Identifiers for Advertisers (“IDFA”) o Android Advertising ID. Por consiguiente, la trazabilidad de los móviles es equivalente a la de los ordenadores y aún mayor como veremos más adelante.
Beacons
Los beacons o web-beacons son imágenes que se insertan en una página para hacer una llamada oculta a otra página que recaba estadísticas. Normalmente los beacons son invisibles para el usuario, pero pueden ser también imágenes visibles. Por ejemplo, el propietario de un sitio web puede poner un botón estilo [Ver en Amazon] el cual informará a Amazon de que un usuario ha visitado una determinada página. El sitio web de un tercero no puede leer las cookies de Amazon, y Amazon no puede leer las cookies de terceros. Pero un sitio web sí puede leer sus propias cookies y enviárselas a Amazon. Y cómo las cookies de Amazon siempre se envían a Amazon en cada petición, existe una forma sencilla de casar las cookies si ambas partes, el sitio web y Amazon, están de acuerdo.
Audio Beacons
Los audio beacons, también conocidos como ultrasonic cross-device tracking (uXDT) consisten en emitir ultrasonidos imperceptibles para el oído humano pero que sí son captados por otro dispositivo electrónico. Se usan principalmente para vincular dispositivos. A fecha de mayo de 2017 existen identificadas más de 200 aplicaciones para Android que usan ultrasonidos. Se pueden usar, por ejemplo para detectar cuando una persona entra en una tienda colocando un dispositivo emisor al cual el móvil del usuario responde mediante una app preinstalada.
Almacenamiento local HTML 5
A partir de HTML 5, las aplicaciones pueden hacer uso de un tipo de almacenamiento local atributo-valor, pensado para aplicaciones a las que les resulta conveniente almacenar una cantidad considerable de datos en el navegador web. El almacenamiento local se puede usar con los mismos fines de seguimiento que las cookies si el navegador cliente tiene JavaScript activado.
Geolocalización y Redes WiFi
Otra de las novedades de HTML 5 fue la geolocalización del navegador cliente. Esta requiere consentimiento del usuario, aunque se puede autorizar a un sitio permanentemente o autorizar a todos los sitios siempre. La geolocalización utiliza diversas técnicas: la dirección IP, la red WiFi, datos GPS (si es un dispositivo móvil). El navegador envía estos datos al proveedor de geolocalización (que por defecto suele ser Google Location Services) quien devuelve una ubicación estimada del dispositivo aunque sin garantía de que sea exacta.
Incluso sin la geolocalización activada, el sitio web visitado puede conocer dirección IP de la red WiFi utilizada. Por ejemplo, supongamos que en una casa se comparte un dispositivo para navegar por Internet. Entonces, en principio, no se puede saber quién lo está usando en cada momento. Pero si el dispositivo aparece cada mañana en un Starbucks y cada tarde en una estación de tren, y los contenidos visualizados en ambos casos son diferentes, entonces es posible inferir que uno de los miembros de la casa usa el dispositivo por las mañanas y el otro por la tarde. O también, si hay dos dispositivos que siempre aparecen juntos por pares en las mismas redes WiFi de una estación de tren o un aeropuerto entonces es casi seguro que ambos pertenecen al mismo usuario.
Información sobre el navegador (fingerprinting)
Una de las cosas que se envía en las cabeceras HTTP es información sobre el navegador web que está siendo utilizado por el usuario. Esta información es bastante detallada, incluye no sólo la marca y versión exacta, sino también la resolución de pantalla y los plug-ins instalados. Las diferencias en la configuración del navegador pueden usarse para caracterizar y distinguir usuarios. Algunos ejemplos de la información que puede obtener un sitio web de nuestro propio navegador pueden comprobarse visitando noc.to, panopticlick.eff.org, amiunique.org.
Además de la información sobre el navegador, se puede utilizar una técnica adicional conocida como canvas fingerprinting descrita públicamente por primera vez en el artículo The Web Never Forgets publicado en 2014 y que se basa en un exploit de HTML 5 y el uso que hace de la GPU.
En mi caso concreto, todos los sitios con demos de fingerprinting fueron capaces de identificar unívocamente mi navegador, principalmente debido a que uso una versión beta de Firefox, varios plug-ins poco comunes y, sorprendentemente, porque mi nivel de contramedidas para eludir la publicidad es inusualmente alto.
Es decir, la propia configuración diseñada para defenderme le acaba diciendo al anunciante quién soy, igual o acaso incluso mejor que una cookie.
Lo mejor para evitar el fingerprinting es usar Tor aunque deshabilitar la ejecución de JavaScript también priva a los sitios de la mayor parte de la información necesaria para identificar sin lugar a dudas a un navegador.
Información puesta por la cámara en las imágenes (metadatos JPEG)

Metadatos JPEG
Las imágenes JPEG tomadas con una cámara digital contienen una gran cantidad de información relativa a dónde y cuándo se tomó la fotografía y con qué dispositivo. Esta información se puede utilizar para obtener un
fingerprint que identifica la huella de la cámara de forma similar a cómo se identifica la huella del navegador, pero como se puede apreciar en el ejemplo hay muchísimo más.
Flash, Applets Java y controles ActiveX
Los sitios web que usan Flash pueden mantener sus propias cookies y almacenamiento local diferentes de las cookies y el almacenamiento local HTML 5. Esta información puede limpiarse desde el administrador de Flash en el Panel de Control de Windows. También es posible indicarle a Flash que los sitios web no pueden guardar información en el navegador cliente.
Tanto Java como ActiveX en Internet Explorer son tecnologías que también pueden usarse para almacenar información de seguimiento. Aunque teóricamente los applets y los ActiveX pueden correr dentro de un sandbox de seguridad, en el pasado hubo tantos problemas con virus y programas malintencionados que se colaban a través de Java y ActiveX que los fabricantes de navegadores acabaron desactivando el soporte por defecto para Java y ActiveX.
Plug-ins, toolbars y spyware
La forma más extrema en la que un agente externo puede obtener información de un navegador cliente es mediante la instalación de una extensión en el navegador que espíe al usuario. En este caso el espionaje puede ir mucho más allá de los sitios visitados e incluir una inspección de todos los archivos que el usuario tenga en su disco duro.
Historial de navegación, búsquedas, archivos temporales, etags
En principio, el historial de navegación no está disponible para los sitios que se visitan. Pero esto es sólo asumiendo que no se haya instalado un plug-in espía que envíe esta información. El historial, por tanto, sólo es útil normalmente con fines forenses pero no con fines publicitarios. Todos los navegadores permiten limpiar el historial, al menos en teoría, porque en la práctica aunque parezca que se haya borrado por completo, todos los navegadores dejan trazas en el disco duro que son fastidiosamente difíciles de eliminar.
Los archivos temporales (cache) en principio tampoco es accesible por los sitios web visitados y no existen (o yo no conozco) casos en que se hayan usado para seguir a los usuarios. No obstante, como el historial, los archivos temporales no desaparecen por completo cuando el usuario los borra desde el navegador y, por consiguiente, si se tiene acceso a la máquina, son otra fuente de información forense acerca de la actividad del usuario.
Sin embargo, si existe una característica del cache de los navegadores que puede usarse para seguir a los usuarios: los Etags. Estos son una funcionalidad opcional del protocolo HTTP. El uso para el que fueron creados es mejorar la eficiencia de los caches. En la cabecera de la respuesta a cada petición HTTP el servidor puede incluir un etag. Se trata de un valor arbitrario calculado por el servidor que debe cambiar cuando cambia el recurso (la página web) solicitado. Antes de descargar nuevamente un recurso cacheado, el cliente envía su etag al servidor. Si el etag del cliente y el del servidor coinciden entonces el cliente puede suponer que su versión cacheada coincide con la última versión en el servidor y, por consiguiente, no es necesario descargar nuevamente el recurso. Entonces para trazar a un usuario lo único que necesita hacer el servidor es asignar el mismo etag a todas las páginas la primera vez que lo ve y luego devolver el mismo etag que recibe (u otro etag nuevo que el servidor pueda asociar con el anterior). Eludir los etags es casi imposible porque para ello habría que desactivar el cache de los navegadores, aunque es posible deshacerse de ellos periódicamente simplemente vaciando el cache. Su inevitabilidad ha causado que varias empresas que los usaban hayan sido objeto de sendas demandas civiles tras las cuales la legalidad de los etags está, como mínimo, severamente en entredicho.
Big G
Google guarda un historial con todas las búsquedas realizadas tanto en el buscador principal como en YouTube. Si se tiene activada la geolocalización, Google también guarda un historial de todos los sitios donde hayamos estado. Si no se ha indicado a Google que no guarde el historial de búsquedas y localizaciones, una visita a myactivity.google.com puede ser aterradora. Afortunadamente, es posible prohibir a Google a que se acuerde de nuestras búsquedas y ubicaciones o, al menos, que parezca que se ha olvidado de ellas, porque yo personalmente no estoy para nada seguro ni de que no las guarde ni de que las borre cuando se le indica que lo haga.
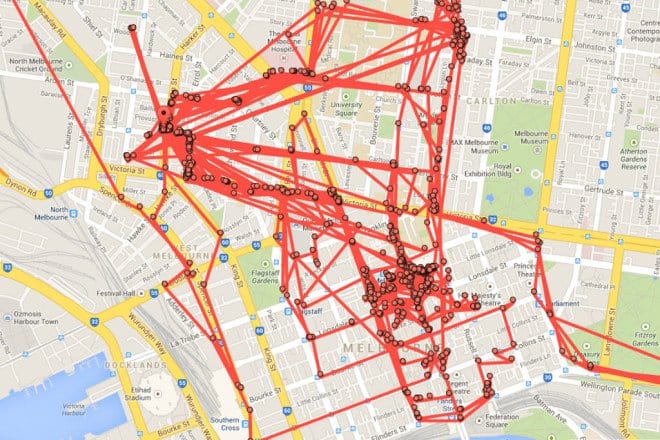
Ejemplo de historial de localizaciones en Google.
Además del buscador, Google cuenta con otras cuatro grandes bazas para el seguimiento: GMail, Google Analytics, Google Location Services, y su servidor de DNS 8.8.8.8
Con GMail porque legalmente pueden leerse los correos y ceder datos contenidos en ellos, si, en un documento legal de 2013 se establece que “a person has no legitimate expectation of privacy in information he voluntarily turns over to third parties”. Aunque muy recientemente la Unión Europea ha presentado una nueva iniciativa para prohibirle a Google que se lea los correos con fines publicitarios.
Con Google Analytics porque aunque el navegador cliente no le diga a Google quien es el visitante, el servidor donde está instalado Google Analytics sí lo hace cuando reconoce al visitante.
Con Google Location Services porque el navegador envía datos a Google cuando un sitio hace una petición de geolocalización.
Y con el servidor de DNS 8.8.8.8 (si se usa) porque el DNS puede acordarse de qué IP cliente le pidió que convirtiese la URL de un sitio en la dirección IP del sitio. Una forma de ver los DNS a través de los que estamos accediendo a Internet es consultar la página web www.dnsleaktest.com.
Whatsapp y Facebook
Un caso que merece atención especial es el de la interacción de Whatsapp con Facebook. En general, Whatsapp es considerado inseguro y muchas empresas prohíben expresamente su uso para comunicaciones de negocio.
Whatsapp empezó como una empresa bastante preocupada por la privacidad. Su modelo de negocio no se basaba en la publicidad sino en cobrar a los usuarios una pequeña cantidad anual y a otros incumbentes, como los bancos, por enviar el equivalente a un SMS al usuario. Eso fué así hasta que Facebook compró Whatsapp por 19.000 millones de dólares. Que se sepa, Whatsapp no analiza las conversaciones de los usuarios como hace GMail. Ni tampoco guarda un histórico. Como mucho, las almacena durante un máximo de 30 días si el destinatario no se encuentra disponible. No obstante, con el último cambio en la política de privacidad, se autorizaba a Whatsapp a compatir con Facebook todos los números de teléfono en el agenda del usuario. El número de teléfono es un dato muy relevante para los anunciantes porque permite asociar al internauta con un cliente que ya exista en la base de datos interna del comprador de la información. Otros usos son la sugerencia de amigos nuevos en Facebook basándose en los números de teléfono, lo cual podría inducir a sugerencias de personas que no deberían aparecer en la lista de amigos potenciales por cuestiones de privacidad.
Una forma de inspeccionar la información que Facebook está recabando sobre nosotros mientras lo utilizamos es instalar el plug-in Data Selfie para Chrome (cuyo código fuente está disponible en GitHub). Data Selfie envía de forma anónima los datos al servicio Apply Magic Sauce de IBM Watson el cual devuelve el perfil de personalidad del internauta inferido de sus datos de navegación.
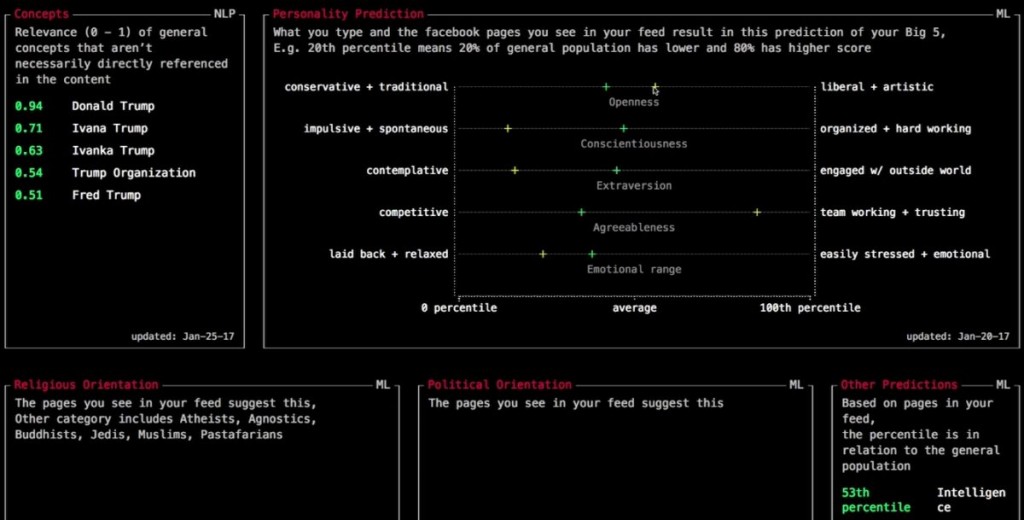
Predicción de personalidad elaborada por Apply Magic Sauce
Telemetría de Windows 10
Desde que se lanzó la actualización gratuita (y casi forzosa) a Windows 10, Microsoft ha sido sospechosa de convertir a los usuarios en mercancia. Según se intuye leyendo la licencia de Windows 10, y Microsoft no lo ha desmentido, esta versión del S.O. puede enviar a Microsoft información sobre todas las páginas web visitadas por el usuario, y, además, no existe ninguna forma de impedirlo. Si se usa Windows 7 u 8 y se tiene instalado alguno de los parches KB3068708, KB3022345, KB3075249 o KB3080149 y se participa en el Programa de Mejora de la Experiencia de Usuario, entonces también se envía informacion de telemetría a Microsoft. En principio, toda esta información es anónima, es decir, Microsoft recolecta, por ejemplo, cuánto tiempo tardó una aplicación en abrirse y cuánto tiempo estuvo usándola, pero no mantiene vinculada esa información al usuario que la generó. Una opción para evitar que Windows envíe datos a Microsoft es instalar un firewall de terceros para cortar las comunicaciones entre el ordenador personal y Microsoft. En lo que se refiere a la privacidad, lo más peligroso de Windows 10 parece ser el asistente virtual Cortana, ya que el navegador Edge envía a Cortana la lista de todas las páginas visitadas, aunque esta funcionalidad sí se puede deshabilitar.
Inspección profunda de paquetes de los ISP
Un incumbente en una posición muy privilegiada para obtener datos de los usuarios sin que se enteren son los ISPs (Internet Service Providers). A fin de cuentas, todo el tráfico entrante y saliente de un usuario pasa necesariamente por su ISP quien puede usar técnicas de inspección profunda de paquetes. Si el tráfico está (bien) encriptado, el ISP no puede saber lo que contiene pero como mínimo puede inspeccionar todas las URLs solicitadas por el usuario. Dos compañías Phorm y NebuAd fueron especialmente notorias en el pasado por sus alianzas con ISPs para recabar datos mediante inspección profunda de paquetes pero debido a las advertencias de los reguladores legales tuvieron que cesar dicha actividad.
Información obtenida fuera de Internet
Por detrás de la información que se genera mientras el usuario navega por Internet, la segunda fuente de datos valiosos para los anunciantes es la información que proviene de las tarjetas de crédito y fidelización. En principio, está prohibido facilitar información a los bancos y aseguradoras que sirva para determinar nuestra calificación de riesgo y haya sido obtenida sin conocimiento y consentimiento del interesado. Pero los bancos y minoristas aún pueden obtener y manejar grandes cantidades de datos. American Express, en concreto, goza de una pequeña ventaja, ya que el usuario debe conectarse a la web de American para comprobar su saldo y puntos en lugar de consultar los extractos bancarios, lo cual da la oportunidad a American de colocar una cookie propia con la que seguir al usuario. La empresa Acxiom, por ejemplo, proporciona un servicio a las tiendas mediante el cual solo con el nombre que figura en la tarjeta de crédito y un código postal facilitado voluntariamente por el comprador, se puede obtener la dirección postal del propietario de la tarjeta de crédito sin necesidad de pedírsela directamente.
Las compañías como Equifax y Experian solicitan a los empleadores detalles salariales como parte del proceso de evaluación de riesgos de empleados.
También se recopila información de directorios y registros públicos, publicaciones estatales, encuestas, subastas, etc. En 2016 incluso se decretó una normativa europea que obliga a las compañías aéreas a ceder datos personales sobre sus pasajeros con fines de seguridad.
Por último, los dispositivos domóticos como el Alexa de Amazon pueden proporcionar una gran cantidad de información sobre los usuarios según ya explicábamos en otro artículo de 2016.
Información ligada a eventos
Los anunciantes saben que no solo es preciso llegar a la persona adecuada con el mensaje adecuado sino también hacerlo en el momento oportuno. Por ello se recopila también información que proporcione pistas acerca de los hábitos de las personas y de lo que harán en un futuro próximo. Por supuesto Google lo puede intuir desde siempre mirando el historial de búsquedas que almacena para cada usuario. Pero otras compañías como Equifax venden bases de datos de personas que serán padres en un futuro próximo incluyendo su calificación crediticia.
Brechas de seguridad
Un última fuente de datos muy valiosos para los anunciantes y los defraudadores son las brechas de seguridad. En 2013 en Yahoo! Se vieron comprometidas 1.000 millones de cuentas de correo y luego otros 500 millones de nuevo en 2014. De portal de contactos Ashley Madison fueron robados en 2015 25Gb incluyendo datos de 32 millones de usuarios que fueron hechos públicos. Y eso solo son dos ejemplos conocidos, pero es imposible saber cuántos robos ha habido que no hayan sido detectados ni denunciados.
Trackers
La información recogida mediante las técnicas anteriormente enumeradas es recopilada por los trackers que son pequeños fragmentos de código HTML y JavaScript que los sitios insertan en sus páginas web.
Existen muchísimos trackers, según un estudio de TRUSTe, hay cerca de
1.300 empresas monitorizando las 100 webs con mayor tráfico de Internet.
Wall Street Journal también publicó una tabla con la cantidad de trackers en las webs más populares que muestra que en una web típica hay varias decenas de trackers.
Los navegadores tienen una opción «Do not track» que indica a los sitios web que el usuario no quiere que le sigan online. Pero esta opción es mayormente inútil porque los sitios web no tienen obligación de respetarla, sino que lo hacen solo si quieren por respeto a las preferencias del usuario.
2. Qué se puede hacer para protegerse contra el seguimiento
En fácil intuir lo complicado que resulta protegerse contra el arsenal de técnicas de seguimiento descritas. Lo más eficaz es usar el navegador Tor, que incluye de serie medidas anti-fingerprinting, deshabilitar JavaScript y almacenamiento HTML 5 y prohibir todas las cookies. Esto provocará que dejen de funcionar casi todos los sitios web que habitualmente visitamos, incluídos los periódicos, la web del banco y cualquier pago online. Por consiguiente, no es una opción práctica.
Usando Firefox, podemos tomar las siguientes medidas, que son parecidas para Internet Explorer, Chrome y Safari.
1. Limpiar y deshabilitar las cookies. Excepto para los sitios de confianza. Firefox proporciona una lista blanca de sitios de los cuales se aceptan cookies.
2. Instalar el plug-in NoScript para impedir selectivamente la ejecución de JavaScript. En cada página autorizar solamente la ejecución de scripts que procedan del sitio visitado o, como mucho, de Fuentes externas de confianza como las Content Delivery Network (CDN) de algunas librerías JavaScript comunes.
3. Instalar el plug-in AdBlock o Ghostery para impedir las llamadas a web beacons. Con Ghostery hay que tener cuidado porque, a menos que se le indique lo contrario, la propia Ghostery recopila información estadística sobre los sitios bloqueados y se la vende a los anunciantes. Además, a mi Ghostery me ralentiza visiblemente el navegador y tiene tendencia poner la CPU al 100%, mal asunto cuando estoy de viaje y quiero ahorrar batería. Ghostery tampoco permite personalizar los filtros. De modo que yo recomendaría AdBlock. No confundir AdBlock con AdBlock Plus, ya que este último es sospechoso de cobrar a los anunciantes por incluirles en su lista blanca.
4. Instalar el plug-in Stop Fingerprinting para limitar la información útil para fingerprinting que se envía a los sitios visitados.
5. En las opciones de seguridad, deshabilitar Bloquear contenido peligroso y engañoso, ya que lo que hace esta opción es enviar las URLs visitadas a un servicio de Mozilla que califica si son potencialmente dañinas.
6. Desactivar la geolocalización. Para ello, en la barra de direcciones de Firefox introducir about:config buscar la clave geo.enabled y ponerla en false.
7. Usar el modo Private Browsing de Firefox (Incognito Mode en Google Chrome on InPrivate Browsing en Internet Explorer). En este modo las cookies no se guardan una vez cerrada la sesión y Además la sesión privada no se comunica con las otras sesiones, de modo que aunque se tenga una session abierta con Facebook o Gmail esta no podrá acceder a lo que se esté navegando en privado.
8. Limpiar períódicamente el cache del navegador y la lista de super cookies con CCleaner.
9. Deshabilitar el seguimiento de actividad de Google y nunca navegar con una sesion abierta en GMail o YouTube. Usar otro buscador como DuckDuckGo o PrivateLee.
10. Si se usa Windows 10, no crear una cuenta con Microsoft durante la instalación. O borrarla después de crearla. También deshabilitar Cortana. Instalar un firewall adicional como ZoneAlarm o TinyWall probablemente no merece la pena, pero es una opción para los usuarios más paranóicos y si el PC viene con software Norton o Kapersky, probablemente ya tiene instalado un firewall que se puede configurar. Existe también software de propósito específico como Destroy Windows 10 Spying que deshabilita el keylogger e impide el envío de datos a URLs de Microsoft.
11. Para ocultar la dirección IP propia lo mejor es usar un servicio de VPN como TUVPN.
12. Usar una cuenta de correo especial sólo para registrarse en los sitios web, desde la que no se envíe ni se reciba ningún mensaje. No vincular esta cuenta a ninguna información personal.
3. Técnicas de publicidad personalizada
En ingles al conjunto de técnicas utilizadas para mostrar anuncios basados en el historial de navegación de un usuario se lo conoce como online behavioural advertising (OBA) o behavioural targeting (BT). No he conseguido encontrar ninguna traducción al español que me guste entre «publicidad comportamental en línea», «publicidad conductual en línea», «publicidad en línea basada en el comportamiento», «publicidad selectiva basada en el comportamiento», etc. De modo que en lo sucesivo me voy a referir a ella simplemente como publicidad personalizada. Pues me parece más acertado aludir a su finalidad en lugar de a su método.
La publicidad personalizada hace uso tanto del perfil como de la actividad reciente del usuario. La publicidad de toda la vida ha hecho uso del perfil, ya que incluso en televisión se sabe aproximadamente qué porcentaje de televidentes serán hombres o mujeres, adultos o niños, etc. Para la mayoría de los productos de consumo masivo, afinar el perfil de la audiencia por encima de un determinado umbral no mejora espectacularmente los resultados ya que usualmente hay varios perfiles de comprador. Lo que sí mejora la eficacia es saber qué tiene en mente cada persona cuando está viendo un anuncio.
La finalidad de la publicidad personalizada es mejorar la tasa de conversión, es decir, el ratio entre usuarios que ven un anuncio y los que realmente acaban comprando el producto anunciado o, al menos, son influidos para tomar una decisión de compra posterior.
Podemos postular que la tasa de conversión estará relacionada con la relevancia. Esto es verificable empíricamente y de hecho está más que comprobado que la publicidad personalizada consigue ratios de conversión entre un 30% y un 300% superiores a la publicidad insensible al comportamiento del usuario. Entonces lo que se necesita para mejorar la eficacia de la publicidad es una buena métrica de relevancia.
En términos generales, habrá un conjunto de productos P₁, P₂, P₃ … Pn y un conjunto de usuarios U₁, U₂, U₃ … Um caracterizados por una serie de atributos A₁, A₂, A₃ … Ak. La función de relevancia 𝒇: (P,U) → ℝ devolverá un valor real para cada par de producto y usuario. Y dado un usuario el problema consiste en encontrar el producto P que proporciona el valor máximo para esta función.
La forma de la función de relevancia es, en general, desconocida, aunque hablaremos más adelante sobre qué hace a un mensaje más o menos relevante para un receptor. Además puede haber atributos del usuario que son desconocidos. Por consiguiente, lo que se usa para casar usuarios con productos es inferencia estadística.
Segmentación
La segmentación es la técnica más utilizada para la clasificación de clientes potenciales. Prácticamente todos los proveedores de información comercial y plataformas de anuncios siguen vendiendo segmentos que son más o menos configurables por el comprador de la publicidad.
La segmentación no siempre se hace como la gente tiende a imaginar. Por ejemplo, podría suponerse que el segmento óptimo para unas zapatillas de correr son aquellos internautas que visiten con frecuencia páginas y noticias sobre maratones. Pero también es posible suponer que alguien que visita páginas sobre dietas está gordo y necesitará unas zapatillas para adelgazar corriendo. Personalmente, creo que el uso más infame que he visto de estas hipótesis negativas es la publicidad de pruebas de embarazo dirigida a adolescentes accidentalmente embarazadas.
Los segmentos se forman tomando uno o más atributos. Un segmento obvio es el género masculino o femenino. También se puede segmentar, por ejemplo, según el código postal, ya que las personas que viven en la misma calle tienden a estar en el mismo rango de edad y a tener un perfil familiar y nivel de ingresos parecidos.
En la publicidad personalizada de lo que se trata es de inferir a qué segmentos pertenece un usuario a partir de qué páginas visita o incluso descubrir nuevos segmentos.
Extracción automática de segmentos y anuncios relevantes para ellos
Veamos un poco una posible forma en la que podría funcionar la segmentación automatizada tomada de [1].
Supongamos que tenemos el anterior conjunto de usuarios U₁, U₂, U₃ … Um y asimismo un conjunto de páginas Web W₁, W₂, W₃ … Wl. Cada página web podría pertenecer a una o más categorías C₁, C₂, C₃ … y las categorías se podrían asignar manualmente o se pueden inferir contando la frecuencia de cada palabra en la página o mediante técnicas aún más sofisticadas. Pero por ahora no nos detendremos en la categorización.
Primero construiremos una matriz M ∈ ℝm×l en la que cada elemento mij = (log(#veces que el usuario i ha hecho clic en la URL j) + 1) × log(l / #de usuarios que hicieron clic en la URL j). Cada fila de la matriz representa entonces a un usuario.
Por otra parte tendremos un conjunto de anuncios de productos P₁, P₂, P₃ … Pn
Si no tenemos inicialmente ninguna pista sobre la relación entre el comportamiento de los usuarios y los anuncios que ven, empezaremos mostrando anuncios de forma aleatoria e iremos contando en qué anuncios ha hecho clic cada usuario.
Seguidamente definiremos una métrica de similitud entre usuarios, que solo como ejemplo, podría ser la distancia euclídea entre los vectores que representan a cada usuario en la matriz.
Con todos estos elementos podemos determinar cómo de presuntamente similar es el usuario Fulanito al usuario Menganito y, dado que sabemos en qué anuncios ha hecho clic cada uno de los usuarios, presuponer que los usuarios similares mostrarán tendencia a hacer clic en los mismos anuncios.
Para medir los resultados primero definiremos una función
𝜹: (Um,Pn) → {0, 1}
tal que
𝜹(Um,Pn) = 1 si el usuario Um ha hecho clic en el anuncio Pn
y 𝜹(Um,Pn) = 0 si el usuario no ha hecho clic.
Con esta función si vn es la cantidad total de usuarios que han visto el anuncio Pn definiremos el click through rate como
CTR(Pn) = 1/vn ∑ 𝜹(Um,Pn)
Que en palabras sencillas equivale a decir que si el anuncio ha sido mostrado 6 veces y 3 usuarios hicieron clic en él entonces el CTR es ½.
Si la segmentación ha sido eficaz, lo que se observará es un incremento en el click through rate de los anuncios tras dirigirlos específicamente a los usuarios que forman parte del target más probable.
No obstante, el CTR por sí sólo no es suficiente. Supongamos que hemos hallado un segmento Sr para el cual el CTR de un anuncio Pn es mayor. Lo cual escribiremos como CTR(Pn|Sr) > CTR(Pn). Esto sólo pone de manifiesto que existe un segmento de usuarios Sr que está más interesado en el anuncio Pn que la media del resto de los usuarios. Pero no implica que se hayan hallado todos los segmentos significativos de usuarios. Estadísticamente diríamos que el CTR es una medida de la precisión pero no de la exhaustividad (recall).
Para poder calcular el Valor-F, podríamos definir la exhaustividad (REC) como la suma de todos los valores de 𝜹 para todos los usuarios del segmento Sr que han visto el anuncio Pn dividida de la suma de los valores de 𝜹 para todos los usuarios que han visto el anuncio.
Y el Valor-F que pondera la precisión y la exhaustividad será entonces el habitual
F = 2 · Precisión · Exhaustividad / (Precisión + Exhaustividad)
que en nuestro caso particular para un anuncio P
n y un segmento S
r se convertirá en
F(Pn|Sr) = 2 · CRT(Pn|Sr) · REC(Pn|Sr) / (CRT(Pn|Sr) + REC(Pn|Sr))
Intuitivamente, es razonable suponer que los clics en un anuncio tenderán a provenir de los usuarios de determinados segmentos. Pero podría también suceder que la distribución de clics fuese uniformes a través de todos los segmentos, en cuyo caso la segmentación no serviría para nada. Una últimamétrica fundamental que necesitamos es pues la entropía, con la que será posible comparar la eficacia de diferentes segmentaciones. Sea vr la cantidad de usuarios del segmento Sr que han visto el anuncio Pn. Entonces la probabilidad de que un usuario U del segmento Sr haga clic en el anuncio Pn es
𝛒(Sr|Pn) = 1/vr ∑ 𝜹(Um,Pn)
Con esta probabilidad podemos usar la definición matemática de entropía
E(Pn) = – ∑r 𝛒(Sr|Pn) · log 𝛒((Sr|Pn))
A mayor entropía más uniformemente distribuidos están los clics en un anuncio a través de todos los segmentos.
Por supuesto, este es un modelo muy simplificado. Un modelo real tendrá en cuenta no sólo las páginas visitadas sino también el tiempo empleado en cada página, lo reciente que sea la última visita, la frecuencia con la que se visita la misma página, la cantidad de otras páginas vistas en el mismo sitio web, etc. No siempre lo relacionado con lo más recientemente visitado es lo que se anuncia al usuario. Algunos anunciantes eligen diferir la publicidad para que no sea evidente al usuario que está siendo seguido online.
El problema de la segmentación basada en CTR es que hace clic en un anuncio es un evento muy poco frecuente que puede rondar por algo como el 0,1% de las páginas vistas. Por ello veremos a continuación cómo se puede seguir extrayendo información relevante para la personalización aunque poco o ningún usuario hayan hecho clic en un anuncio determinado.
Personalización basada en interacciones sociales
Evidentemente, los likes en Facebook y Twitter pueden considerarse equivalents a una página vista con puntuación positiva sobre las preferencias de usuario. Pero de las redes sociales se puede extraer mucha más información. En primer lugar, debido a un fenómeno conocido por los sociólogos como homofilia, los amigos presentan normalmente similitudes en muchos rasgos: edad, lugar de residencia, intereses, … es decir, para que sepan de ti no hace falta que le cuentes a Facebook nada de lo que haces pues tan sólo viendo lo que hacen tus amigos es posible inferir que tú harás cosas parecidas.
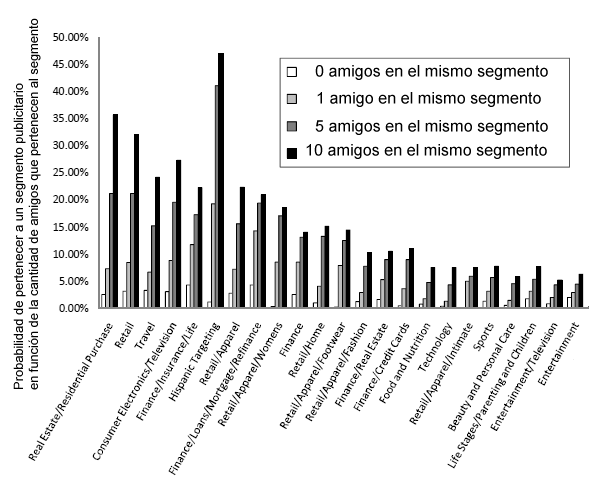
Fuente: Large-Scale Behavioral targeting with a Social Twist (Kun Liu & Lei Tang)
Teoría de la relevancia
No voy a extenderme más sobre las técnicas estadísticas para la personalización de publicidad, pero antes de ir terminando, me gustaría hacer una brevísima parada en la teoría de la relevancia de Wilson y Sperber según la cual un receptor de un mensaje lo procesará mentalmente hasta que le encuentre un significado y entonces dejará de prestarle atención. Además, el estímulo publicitario debe de cumplir dos requisitos: 1º) el estímulo debe de ser lo bastante fuerte como para motivar el esfuerzo de entenderlo, y 2º) el estímulo debe ser compatible con las capacidades y preferencias del destinatario. Simplemente quiero detenerme aquí para recordar que ninguna técnica de optimización estadística salvará al anunciante de un mal mensaje.
Retargeting
El retargeting es el equivalente online a que una persona entre en una tienda atraída por su escaparate pero salga finalmente sin comprar nada. Posiblemente, el visitante sí estaba interesado, pero no encontró exactamente lo que buscaba, o en el ultimo momento abandonó su carrito de la compra –la última vez que trabajé en un sitio de e-commerce en retail había algo así como un 40% de carritos abandonado por gente que había agregado algo a la cesta pero no llegó a completar el pago–. Dado que los anuncios se diseñan para generar tráfico, es posible que el usuario hiciese clic en él por parecerle muy relevante pero luego el contenido no tanto. Esto en la jerga se conoce como tasa de rebote que es el porcentaje de usuarios que abandonan el sitio web tras visitar una sola página por breve tiempo (menos de 1 minuto). Con los «rebotados» es posible que haya poco que hacer, pero es factible recabar más información sobre los usuarios que sí navegaron por el sitio. Con estos últimos lo que se hace es pasar a la plataforma de anuncios más información sobre sus preferencias de manera que en el futuro se les presente otro anuncio más acorde con lo que se ha averiguado acerca de ellos. Esto se consigue colocándole al usuario una cookie de retargeting que se comparte con la plataforma de gestión de anuncios.
Artículos relacionados :
Immaterial Labour and Data Harvesting (Facebook Algorithmic Factory 1).
Human Data Banks and Algorithmic Labour (Facebook Algorithmic Factory 2).
Quantified Lives on Discount (Facebook Algorithmic Factory 3).
Your Facebook data is creepy as hell (Georges Abi-Heila)





 Hace unas semanas me encontraba en medio de un brote de optimismo. Muy contento con los resultados, había invitado a nuestro equipo y a los empleados del cliente a una barra libre de tapas. Entre plato y plato, el jefe de producto me dijo: “Vosotros los consultores externos siempre veis el vaso medio lleno. Porque estais acostumbrados a que os lancen en paracaídas sólo en proyectos que van mal o necesitan desesperadamente recursos. Entonces pensais: ‘Bueno, en peores plazas he toreado’. Pero a los que llevamos quince años aquí nos gustaría que todo fuese perfecto y ese deseo hace que la percepción sea la de vivir permanentemente dentro de un túnel sin salida”.
Hace unas semanas me encontraba en medio de un brote de optimismo. Muy contento con los resultados, había invitado a nuestro equipo y a los empleados del cliente a una barra libre de tapas. Entre plato y plato, el jefe de producto me dijo: “Vosotros los consultores externos siempre veis el vaso medio lleno. Porque estais acostumbrados a que os lancen en paracaídas sólo en proyectos que van mal o necesitan desesperadamente recursos. Entonces pensais: ‘Bueno, en peores plazas he toreado’. Pero a los que llevamos quince años aquí nos gustaría que todo fuese perfecto y ese deseo hace que la percepción sea la de vivir permanentemente dentro de un túnel sin salida”.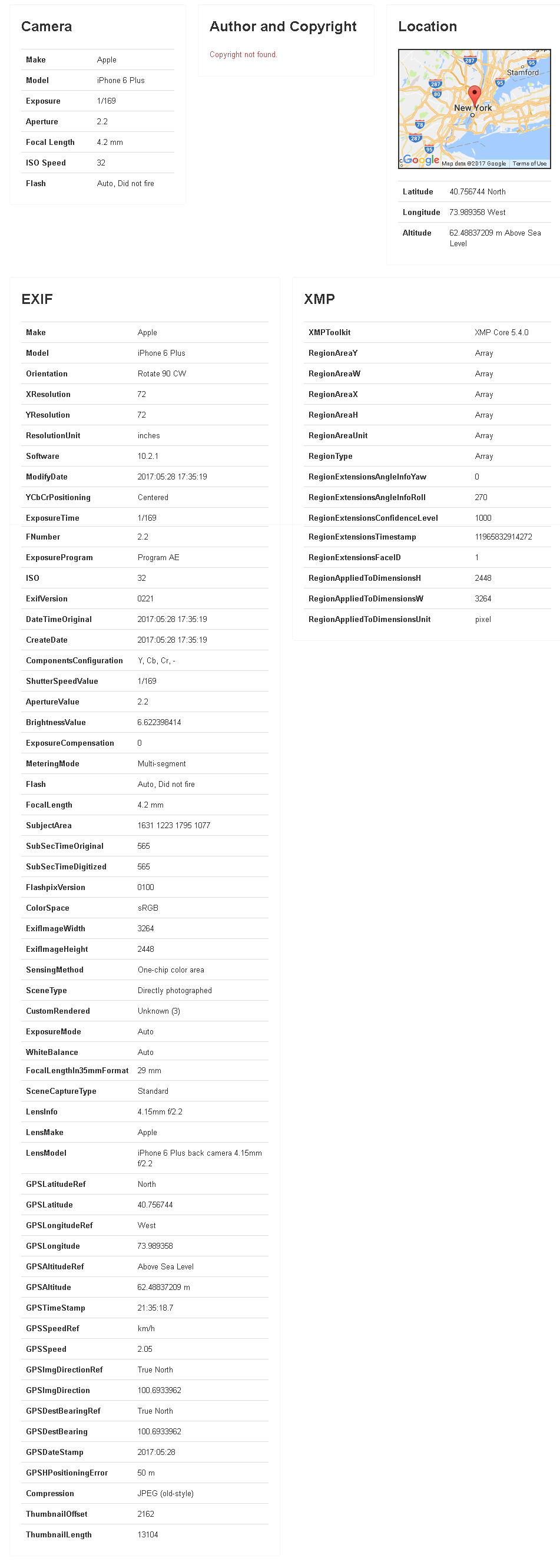


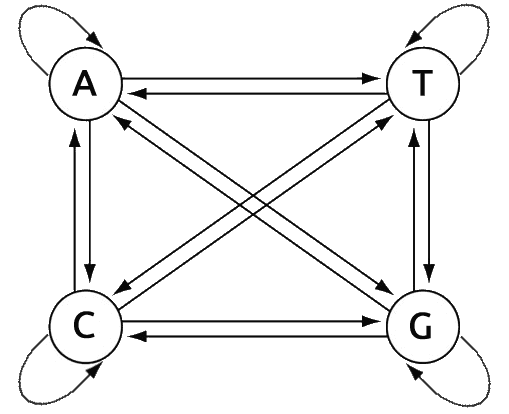
 La
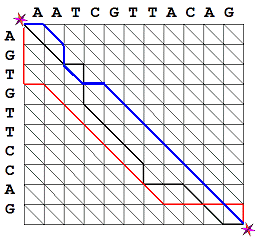
La  Las cadenas de ADN se forman con cuatro nucleótidos: dos purinas, adenina (A) y guanina (G) ; y dos pirimidinas, citosina (C) y tiamina (T). En adelante nos referiremos a estos nucleótidos simplemente como A G C T. Los nucleótidos se enlazan siempre en los mismos pares purina-pirimidina A-T y C-G dentro de la conocida estructura de doble hélice. Cada triplete de nucleótidos forma un
Las cadenas de ADN se forman con cuatro nucleótidos: dos purinas, adenina (A) y guanina (G) ; y dos pirimidinas, citosina (C) y tiamina (T). En adelante nos referiremos a estos nucleótidos simplemente como A G C T. Los nucleótidos se enlazan siempre en los mismos pares purina-pirimidina A-T y C-G dentro de la conocida estructura de doble hélice. Cada triplete de nucleótidos forma un 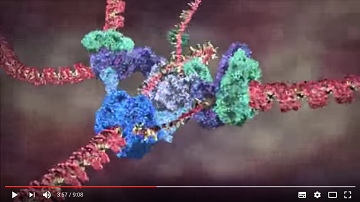


 Fué en una inspiradora charla de José María Gasalla organizada por un ex-presidente de EO-Madrid donde escuché la expresión del “quejido nacional” para referirse a esa gente (o así lo interpreté yo) que es demasiado perezosa como para ser feliz.
Fué en una inspiradora charla de José María Gasalla organizada por un ex-presidente de EO-Madrid donde escuché la expresión del “quejido nacional” para referirse a esa gente (o así lo interpreté yo) que es demasiado perezosa como para ser feliz.

