
Todas las empresas (jóvenes y maduras) tienen un programador que es (presuntamente) muy bueno. Esto a veces es cierto y otras no. Lo único que es invariablemente cierto es que tienen un programador con el ego hipertrofiado a veces hasta el punto de hacerles odiosos. Ya escribí hace tiempo acerca de cómo encontrar y gestionar un partner técnico. El desafío para el director de una empresa basada en software es que es muy difícil evaluar la calidad del trabajo de un programador si tu mismo no eres programador. En este post explicaré cómo debe ser el diseño de una aplicación para que realmente sea escalable. Lo expondré de una manera en que se pueda entender (espero) por cualquier persona sin conocimientos técnicos avanzados.
Almacenes de datos, lógica de negocio, control de flujo y presentación.
Una aplicación se compone de cuatro grandes subsistemas apilados en capas:
1ª) la capa de almacenamiento de datos
2ª) la capa que contiene las reglas y la lógica del negocio
3ª) la capa que define y controla los flujos de trabajo del usuario
4ª) la capa que presenta los datos por pantalla
En principio, a efectos de la escalabilidad, la tecnología empleada en cada capa no es muy relevante. Para el almacenamiento de datos podría ser MySQL o PostgreSQL o SQL Server o una BB.DD. NoSQL. El lenguaje de programación puede ser Java o Ruby o PHP o Python o .NET. El controlador puede ser Struts o Stripes u otro. El servidor web puede ser Apache o Tomcat o IIS, etc.
Lo importante para conseguir escalabilidad no son las tecnologías específicas que se emplean sino la arquitectura del sistema en su totalidad.
Concretamente, las bases de datos relacionales han adquirido cierta mala fama de ser poco escalables en gran parte porque se ha abusado de ellas, utilizándolas para lo que no era. Pero se siguen y se deben de seguir usando. Prácticamente todos los sitios web de alto tráfico hoy en día usan combinaciones de bases de datos relacionales apoyadas por sistemas de almacenamiento distribuido no relacional.
Escalabilidad en el almacenamiento.
El stress sobre la capa de almacenamiento depende de cinco factores:
1º) el volumen de datos
2º) el número de escrituras en disco por unidad de tiempo
3º) el número de lecturas en disco por unidad de tiempo
4º) la complejidad de las consultas ejecutadas contra la BB.DD.
5º) la configuración de los índices en la BB.DD.
Gestión del volumen creciente de datos
Los datos deben subdividirse en datos estructurados (aquellos que se almacenan en tablas y campos) y no estructurados (imágenes, e-mails, documentos, etc.)
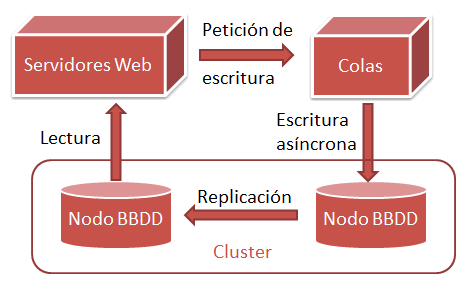
Los datos estructurados se guardan en un sistema de almacenamiento relacional o no relacional. Al principio los datos caben en un único servidor. Cuando se alcanza el límite de capacidad de un servidor hay dos técnicas que se pueden emplear para seguir creciendo: el clustering y el sharding. Un cluster es un conjunto de máquinas que a la vista del programador funcionan como si fuese una sola. El sharding es un particionamiento horizontal de la base de datos mediante el cual diferentes filas de la misma tabla se almacenan en diferentes servidores. Para el programdor los clusters son más sencillos de usar, dado que no tiene que preocuparse acerca de cómo está distribuida la información en los shards. Pero para los técnicos de sistemas, los shards son, en general, menos problemáticos. Aunque últimamente existen soluciones de clustering bastante transparentes, MySQL, PostgreSQL, MongoDB o Apache Cassandra (entre otros muchos) ofrecen clusters que se pueden hacer crecer en número de servidores con bastante facilidad.
Los datos no estructurados se suelen guardar en un sistema de almacenamiento distribuido atributo/valor. Este sistema aisla al programador de la estructura de servidores y directorios subyacente. El más popular es el SaaS de Amazon S3 pero hay muchos más, por ejemplo, hasta 2010 Facebook gestionaba su sistema de mensajes internos con un cluster Cassandra.
Escrituras en disco
Las cuatro reglas para las escrituras en disco son:
1ª) La aplicación irá tanto más rápida cuantas menos sean las tablas en las que tenga que escribir en cada transacción. Una normalización completa del modelo de datos puede causar lentitud debido a que la aplicación necesita escribir en muchas tablas. La velocidad de cada transacción depende del número de filas y tambien del número de columnas. De hecho, para los técnicos, la forma más rápida de escribir en la BB.DD. es meter todos los datos serializados en un único campo binario largo y luego indexarlos por otra parte.
2ª) Todas las escrituras deben ser preferiblemente asíncronas. Es decir, el usuario no tiene que esperar nunca a que se complete una operación de escritura para poder continuar usando la aplicación. Esto requiere normalmente emplear un subsistema de colas como JBoss Messaging o Apache ActiveMQ.
3ª) Las escrituras no deben interferir con las lecturas. Para garantizar la integridad de datos, la base de datos necesita bloquear temporalmente en cada operación una parte de la tabla escrita. Estos bloqueos mientras se escribe retardan las lecturas puesto que estas deben esperar a que terminen las escrituras antes de continuar.
4ª) Debe haber el mínimo número de round trip delays entre el cliente y el servidor. El round trip delay es el tiempo que tarda el cliente (en este caso el servidor web) en alcanzar el servidor de base de datos y recibir una respuesta independientemente del tiempo de proceso que le lleve al servidor de base de datos procesar la petición. Una forma de reducir round trips es escribir en el lenguaje de procedimientos almacenados que proporcione la BB.DD. (PL/pgSQL, Transact SQL o el que sea) las subrutinas de transformación de datos que leen y escriben en la base de datos pero sin presentar datos por pantalla. Los procesos que se ejecutan 100% dentro del SGBDR son mucho más rápidos que los cliente/servidor porque no tienen que cruzar la red ni pasar datos a través de capas como JDBC.
Por último, he conocido programadores que son partidarios de quitar las FOREIGN KEY y controlar la integridad referencial exclusivamennte por código. Yo, personalmente, no soy nada partidario de eliminar las foreign keys pues las ganacias de velocidad en escritura que se obtienen no compensan el riesgo de acabar teniendo datos inconsistentes en la base de datos.
Lecturas de disco
La mejor forma de acelerar las lecturas de disco es no hacerlas gracias a un eficiente sistema de caches. Cuanto más se pueda invertir en RAM para leer todo lo que se pueda de un cache en memoria en vez de acceder a disco tanto mejor. Las propias bases de datos ya incorporan su propio sistema de cache el cual puede ser complementado con caches de nivel superior a la medida de la aplicación.
El tiempo de lectura depende del número de filas y del número de columnas. Ergo limitar ambos aumenta la velocidad. Por ejemplo, hacer SELECT clave,valor FROM tabla WHERE fecha>'2013-01-01' LIMIT 10 será más rápido en PostgreSQL para leer las 10 primeras filas que hacer SELECT * FROM tabla WHERE fecha>'2013-01-01' y luego hacer fetch sólo de las 10 primeras filas en cliente.
Complejidad de las consultas
SQL es un lenguaje con una gran potencia expresiva. Por desgracia dicha potencia también permite escribir fácilmente consultas que saturan el servidor. La saturación del servidor se produce principalmente por dos factores:
1º) Productos cartesianos de dos o más tablas mediante JOIN. JOIN es una sentencia que sirve para casar datos de dos tablas. Por ejemplo, supongamos que tenemos una tabla con direcciones y otra con códigos y nombres de provincias. La tabla de direcciones contiene sólo el código de provincia ’01’,’02’,’03’, etc. pero no el nombre de la provincia. Entonces para recuperar la dirección con el nombre de provincia se escribe algo así como SELECT d.*,p.nombre FROM direcciones d INNER JOIN provincias p ON d.codigo=p.codigo En este escenario, es mucho más rápido desnormalizar el modelo y escribir el nombre de provincia redundantemente en la tabla de direcciones.
2º) Consultas que no pueden usar los índices de la base de datos. Esto se conoce como table full scan. Es decir, para recuperar un subconjunto de filas solicitado en una consulta el servidor necesita leer toda la tabla para encontrar las filas que cumplen el criterio.
Configuración de los índices
En general, no se debe hacer ninguna lectura de la base de datos que no sea bien de una tabla muy pequeña que el SGBDR pueda cachear en RAM, bien de una consulta para la cual el SGBDR pueda usar eficientemente índices. Crear los índices correctamente es una tarea bastante técnica en cuyos detalles no entraré aquí.
Escalabilidad en la lógica de negocio
Los sistemas arquitectónicamente más complejos separan el servidor web de los servidores de aplicaciones de manera que las máquinas que componen la presentación de contenidos al usuario sólo componen la presentación y por otra parte hay otro conjunto de máquinas que trabajan en la preparación y transformación de datos usados por la capa de presentación. En Java el servidor de aplicaciones Open Source más popular el JBoss, el cual, de hecho, combina un servidor web Tomcat embebido junto con un servidor de aplicaciones J2EE y otros servicios. Los servidores de aplicaciones como JBoss se pueden montar en clusters ampliables dinámicamente proporcionando una forma relativamante fácil de ampliar la infraestrutura hardware para atender a un crecimiento de la demanda.
Escalabilidad en la capa de presentación
Al igual que los servidores de aplicaciones, todos los servidores web modernos se pueden configurar en cluster. En la capa de presentación las reglas generales para que sean escalables son las siguientes:
1º) La aplicación debe mantener el mínimo de datos en la sesión. Idealmente, una sesión no debería ser más que una cookie cliente. Yo mismo, nunca escribo aplicaciones que mantienen estados en el servidor. Cuando se tiene un cluster, mantener estados en el servidor implica que los servidores deben sincronizarse entre ellos para mantener la consistencia cuando el cliente continúa por el segundo servidor una operación que empezó en el primer servidor.
2º) Cuidado con las aplicaciones multi-idioma. Meter los literales en la base de datos y acceder a una tabla cada vez que hay que presentar la traducción de uno de ellos es muy mala idea. A mi personalmente Java i18n tampoco me gusta, de modo que hemos acabado desarrollando una solución propia que usa marcas en el código original para generar copias traducidas de las mismas páginas JSP con los literales incluídos de forma estática.
3º) Al igual que con las lecturas de la base de datos, la mejor manera de acelerar la presentación es mantener en un cache todos los datos estáticos que sea posible. Cualquier aplicación que vaya a servir una cantidad apreciable de imágenesu otros datos estáticos debe considerar el uso de una content delivery network (CDN).
Latencia vs. volumen de peticiones
En general, los servidores se optimizan bien para tener bajos tiempos de latencia bien para proporcionar un elevado throughput. La parametrización de timeouts, número máximo de hilos y otras opciones están en el espectro opuesto cuando se trata de minimizar la latencia o de aumentar el throughput.
Cuando se persigue aumentar el throughput la prioridad es el rendimiento global del sistema sin prestar demasiada atención a los tiempos de respuesta a peticiones individuales. Por ejemplo, para un servidor con cuatro núcleos se puede determinar que 200 peticiones concurrentes es el punto óptimo para tener un tiempo medio de respuesta de un segundo. En una configuración orientada a maximizar el throughput se limitaría el número de hilos a 200 y el resto de peticiones concurrentes que llegasen por encima de esa cantidad se encolarían lo cual provocaría que se ralentizase el tiempo de respuesta a determinadas peticiones. Al tratar de maximizar el throughput podría ser que se viole un acuerdo de nivel de servicio que diga, pongamos por caso, que el tiempo máximo de respuesta debe ser de 2 segundos. Para reducir la latencia se podría aumentar el número máximo de hilos de 200 a 300, eso podría provocar que el tiempo medio de respuesta fuese de 1,7 segundos y con ello cumplir el acuerdo de nivel de servicio, aunque el rendimiento global del sistema habría pasado de 200tps a 176tps.
Resumen final de reglas básicas para la escalabilidad
1ª) Los servidores de todas las capas se tienen que poder configurar en clusters o shards sin perjuicio para la aplicación.
2ª) La mayor cantidad posible de procesos deben ser asíncronos.
3ª) Las lecturas y escrituras deben hacerse sobre el mínimo número posible de tablas, filas y columnas. Mediante consultas simples y bien indexadas.
4ª) Deben haber el mínimo tráfico de red entre la base de datos y los servidores web y de aplicaciones.
5ª) Todos los datos estáticos deben ser cacheados.
6ª) La aplicación web no debe mantener estados entre peticiones.





Pingback: Hackers vs. Space Cowboys | La Pastilla Roja
Pingback: Lo que sucede cuando un software se convierte en un agujero negro | La Pastilla Roja
Pingback: Cómo sacar partido al stack big data de Apache | La Pastilla Roja
Pingback: Cómo seleccionar una plataforma de desarrollo para un proyecto web II | La Pastilla Roja