
La fuente más frecuente de conflicto entre el cliente y el proveedor de un desarrollo de software a medida es la diferencia entre las expectativas de plazos, costes y calidad y lo que realmente se entrega. En este artículo presento un modelo sencillo de estimación junto con una plantilla Excel. Todo ello con el fin de reducir sorpresas y frustración. Me hubiese gustado que el texto fuese cómo una simple receta de cocina: 50g de azúcar, 2 huevos, 400g de harina… Pero me temo que la explicación requiere que introduzca algunos conceptos previos antes de llegar a la receta en sí misma.
Para los impacientes, aquí está la plantilla Excel para hacer estimaciones de software, aunque aviso seriamente de que su uso es peligroso si no se manejan bien los principios expuestos a continuación.
Porqué es difícil estimar con fiabilidad
Todavía hoy en día, las estimaciones del esfuerzo requerido para desarrollar un programa tienen casi más de arte que de ciencia. Es posible estimar con precisión cuánto se tarda y cuánto cuesta fabricar un tornillo, esto porque todos los tornillos son iguales, pero en el caso del software cada programa es diferente. Existen, no obstante, varios modelos de estimación maduros y bien conocidos que producen buenos resultados siempre y cuando estén correctamente calibrados.
A la complejidad intrínseca de la estimación, hay que sumar los factores económicos que influyen en el proceso. El mercado del software es cómo el de los coches usados. El cliente evalúa coches de diferentes proveedores. A primera vista todos lucen cómo recién pintando y huelen a nuevo por dentro. El cliente sabe que no todos los coches son efectivamente igual de seminuevos. Y que el vendedor tratará de colocarle aquel vehículo que le reporte mayor beneficio. Por consiguiente, en ausencia de una forma de distinguir entre un vehículo bueno y uno malo, lo más sabio que puede hacer el cliente es elegir el más barato entre los que parecen iguales dado que así al menos minimiza sus pérdidas en el caso de que la compra resulte ser una tartana. Esto induce a los proveedores a bajar precios de forma temeraria en la esperanza de ganar un contrato a pérdida pero obtener beneficio en la actualización y mantenimiento de un software incompleto y defectuoso.
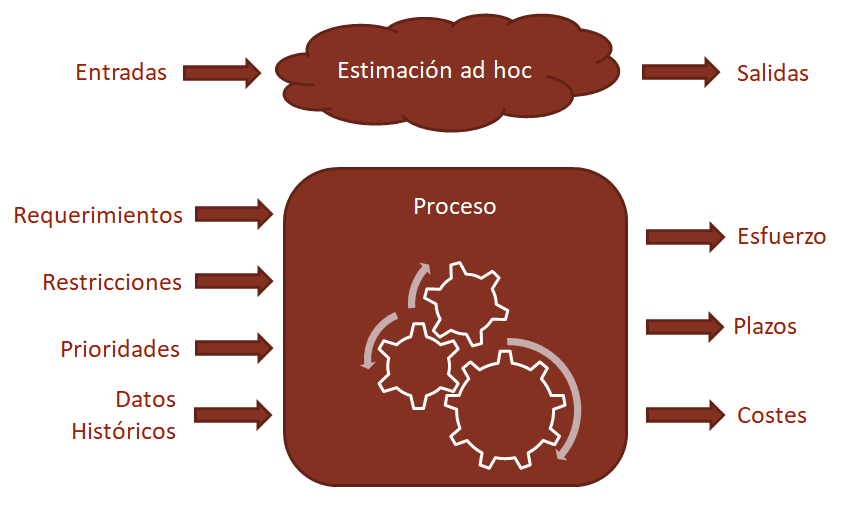
La diferencia entre estimar, planificar y presupuestar
Quien compra un desarrollo lo que quiere saber es cuánto dinero le va costar. Este cálculo requiere tres etapas: 1ª) estimación de esfuerzo, 2ª) planificación de proyecto y 3ª) negociación económica. Aquí vamos a cubrir sólo la parte de estimación de esfuerzo. La razón es quela planificación requeriría otro artículo entero, y la negociación económica, cómo ya he explicado, suele consistir en el regateo gitano más absoluto.
La moda actual es estimar el esfuerzo en unidades abstractas y no en horas/hombre. La razón es que el número de horas requeridas para desarrollar una funcionalidad puede variar (y varía) mucho dependiendo de la naturaleza del proyecto, de la calidad de las especificaciones y de la clase de mano de obra empleada. Por supuesto, al final se convierten las estimaciones abstractas en horas/hombre mediante un proceso que explicaré más adelante.
Proyectos cerrados versus “time & materials”
Los presupuestos de los proyectos suelen presentarse en dos modalidades: 1ª) funcionalidad, precio y plazo previamente acordados, o 2ª) facturación de horas sobre la marcha según se vayan descubriendo necesidades.
Los departamentos financieros suelen abogar porque se compren proyectos cerrados debido a que bien los consideren cómo inversión en activo bien cómo un gasto, les gusta tener una cifra bien defenida que contabilizar. Pero no siempre se sabe a priori todo lo que se necesitará, es más, la mayoria de las veces no se sabe y en principalmente debido a ese desconocimiento inicial que surgieron las técnicas ágiles de desarrollo iterativo facturando al cliente por “time & materials”.
Al proveedor, en realidad, lo que más le interesa no es un proyecto cerrado ni “time & materials” sino cobrarle al cliente por el valor que el proyecto tiene para él. La razones son que el proveedor puede pedir más dinero, ya que el cliente rentabilizará sobradamente la inversión; y no se arriesga con una oferta a la baja en concurrencia competitiva con otros proveedores ni ve sus márgenes erosionados porque el cliente sabe cuánto cuestan realmente las cosas. En consultoría, la regla del dedo gordo para los márgenes es que estos no pueden nunca inferiores al 15% si el encargo se subcontrata enteramente a un tercero ni inferiores al 40% si el proyecto se realiza con recursos propios. Por debajo de estos umbrales mínimos el proveedor está en serio riesgo de acabar perdiendo dinero. Pero si el cliente tiene acceso a la contabilidad analítica del proveedor (sabe cuánto tiempo tarda en hacer algo y cuánto le cuesta la mano de obra por hora trabajada) entonces lo esperable es que el cliente trate de reducir el precio hasta dejar al proveedor en su coste de empresa más un 10%.
Calidad de las especificaciones y retrabajo
Es difícil exagerar la importancia de empezar con unas buenas especificaciones. El mayor porcentaje de problemas con el software proviene de que las especificaciones eran incompletas o erróneas.
Adicionalmente, los diseñadores gráficos saben mejor que nadie que el esfuerzo requerido para completar una tarea está relacionado con la cantidad de decisiones que tenga que tomar el cliente. Paradójicamente, a mayor cantidad de decisiones y responsabilidades por cuenta del cliente mayor coste. Es debido a dos razones: 1ª) que el tiempo empleado en comunicación y retrabajo aumenta y 2ª) que es difícil imponerle el cumplimiento de hitos en plazo al cliente y, por consiguiente, se generan más tiempos muertos de espera.
Definiciones previas
Vamos a introducir a continuación algunas definiciones que necesitaremos para hablar con precisión durante el proceso de estimación.
Objetivos (Targets) : Es lo que se pretende conseguir expresado en términos del valor entregado al cliente.
Funcionalidades (Features): Son las características del software descritas según su comportamiento.
Historias de Usuario (User Stories): Son conjunto de funcionalidades que deben implementarse juntas para alcanzar un objetivo.
Épicas (Epics) : Son grupos de historias de usuario que definen funcionalmente grandes porciones del software.
Estimaciones (Estimates) : Son predicciones de cuanto esfuerzo se requerirá para producir cada funcionalidad.
Planificación (Planning) : Esel proceso de conectar los objetivos con funcionalidades y sus estimaciones para producir un calendario de entregas. Es importante recalcar que las estimaciones no son planes para alcanzar un objetivo. Las estimaciones no deben ser una predicción condicionada por los objetivos de negocio.
Expresiones de probabilidad (Probability confidence statements): Son predicciones sobre el futuro que incluyen una probabilidad de ocurrencia expresada cómo un porcentaje. Cuando debido a una incertidumbre irreducible las estimaciones incluyen una expresión de probabilidad, esta no debeser inherentemente ambigua del estilo «altamente probable» o «muy improbable». Las afirmaciones con probabilidad deben usar un porcentaje: «Llegaremos a esa fecha de entrega con un 85% de probabilidad» incluso si el porcentaje en sí mismo es otra estimación. La razón es que, incluso sin un fundamento cuantitativo para los porcentajes, su uso reduce el número de malentendidos entre las partes. Por consiguiente, los porcentajes no deben interpretarse cómo una probabilidad sino cómo una métrica de lo que tenía en mente quien hizo la estimación.
Rangos (Ranges): Son intervalos de tiempo dentro de los cuales se espera que una funcionalidad esté completada. Los rangos se pueden expresar cómo una Fecha ± X Unidades de Tiempo o cómo un triplete [fecha más temprana de entrega, fecha más probable de entrega, fecha más tardía de entrega] lo cual es equivalente a hablar de mejor caso, caso medio y peor caso. Por convenio, se puede considerar que la fecha más probable de entrega es aquella en la cual la funcionalidad estará lista con más de un 75% de probabilidad y la fecha más tardía de entrega es aquella en la cual la funcionalidad estará lista con más de un 95% de probabilidad.
Definición de «Funcionalidad Lista» (Definition of Ready): La definición precisa de cuándo una funcionalidad está lista para ser entregada, usada y facturada es uno de los aspectos más controvertidos del proceso de desarrollo de software. Cómo mínimo, cada funcionalidad debe haber pasado los tests unitarios del desarrollador, las pruebas de integración de sistemas, las pruebas funcionales del equipo de testeo y la validación del cliente. Pero ningún software está realmente listo para pasar a producción sólo porque haya pasado unas pruebas. Ningún fabricante sensato de automóviles pondría un nuevo modelo en una cadena de producción sólo porque ha pasado algunas horas de prueba en un circuito. Lo que mejor determina la fiabilidad de un software es la cantidad de horas en las que se ha observado su funcionamiento libre de fallos en condiciones de uso reales o indistinguibles de las reales. Además, puede haber requerimientos adicionales para que algo esté listo, por ejemplo:
- Documentación
- Auditoría de seguridad
- Auditoría legal
- Pruebas de carga
- Monitorización y alertas
El estilo de desarrollo
Para el propósito de estimar, se pueden considerar dos grandes tipos de estilo de desarrollo; secuencial e iterativo, que a su vez tienen los siguientes subtipos.
Prototipado Evolutivo Iterativo (Iterative Evolutionary Prototyping): Es el estilo que se emplea cuando los requerimientos no son bien conocidos.
Programación Extrema Iterativa (Iterative Extreme Programming): En este estilo sólo se definen los requerimientos que serán implementados en la siguiente iteración.
Entrega secuencial por etapas (Sequential Staged Delivery): En este estilo la mayoría de los requerimientos se proporcionan al inicio del desarrollo. Un caso especial es el Proceso Unificado Racional (Rational Unified Process, Jacobson, Booch, 1999) en el cual se busca que al menos el 80% de los requerimientos estén bien definidos al inicio.
Entrega Evolutiva (Evolutionary Delivery): Este estilo define cualquier cosa entre no tener casi ningún requerimiento al principio y tenerlos casi todos. Y su acercamiento es bien iterativo, bien secuencial dependiendo de cuántos requerimientos se disponga.
Scrum: Es el estilo de desarrollo más en boga actualmente. Consiste en coger un conjunto de funcionalidades que pueden ser implementadas en un sprint. Un sprint es un intervalo arbitrario de tiempo, pero no muy corto ni muy largo, normalmente entre 15 y 30 días. Una vez que se ha acordado el sprint, el cliente no puede hacer ningún cambio sobre ese sprint. Debido a que Scrum no admite modificaciones sobre la marcha dentro de un sprint, es en parte un estilo secuencial, pero, debido a hay múltiples sprints, es también iterativo.
Factores que afectan a las estimaciones
Si bien las estimaciones de las que tratamos aquí son de índole técnica, existen factores externos que no se pueden ignorar a la hora de realizarlas. Entre los más importantes cabe citar:
- Incertidumbre es las especificaciones.
- Carencia de implicación de los usuarios en la validación de requerimientos.
- Cambios en el alcance y prioridades del proyecto sobre la marcha.
- Capacitación profesional de los recusos humanos empleados.
- Cambios en las plataflormas y herramientas subyacentes.
- Cambios frecuentes de contexto entre actividades no relacionadas.
- Indisponibilidad de terceras partes involucradas en el proceso.
- Claridad de los requerimientos de fiabilidad.
- Requerimientos de documentación.
- Cambios en las dependencias con sistemas externos.
- Tamaño del proyecto.
- Comunicación y reuniones.
Qué contar y cómo contarlo
El método que se propone aquí es hacer algo similar a un escandallo de producción. Se realiza un inventario de las piezas a fabricar, se calcula el coste de cada una por separado y luego se suma. En un proyecto de software hay muchas cosas que pueden considerarse piezas, tanto de alto nivel cómo requerimientos legales, casos de uso, historias de usuario, etc. cómo artefactos técnicos tipo páginas web, tablas en base de datos, informes, etc.
Las piezas que merece la pena contar deben cumplir ciertas características:
-
- Deben estar altamente correlacionadas con el tamaño del software a producir.
- Se debe poder contar antes de que empiece el desarrollo.
- El conteo debe producir una media estadísticamente significativa.
- Contar las piezas debe requerir poco esfuerzo.
Algunos ejemplos de piezas útiles:
-
-
- Casos de Uso
- Historias de Usuario
- Peticiones de Cambio
- Tablas en Base de Datos
- Reglas de Negocio
- Clases
- Servicios Back-End
- Fragmentos del Front-End
- Formularios
- Páginas Web Completas.
- Informes
- Archivos de configuración
- Casos de Prueba
-
A cada pieza se le asignará un tamaño o complejidad, es decir, podemos hablar, por ejemplo, de formularios simples (2-4 campos) medios (4-12 campos) y complejos (+12 campos).
A cada pieza se le asignará una medida del esfuerzo requerido para fabricarla llamada story points. Los story points son una estimación del esfuerzo independiente de los factores que afectan a la productividad. Están fuertemente correlacionados con el número de horas necesarias para producir la pieza, pero no son horas. Los story points sirven para desacoplar la estimación de esfuerzo de la cantidad de tiempo requerido, por ejemplo, digamos que para cavar una piscina de 8×4×2 metros hay que sacar 64m³ de tierra, eso serían los story points: 64. Luego el tiempo necesario para cavarla depende de si lo haces a pico y pala o cuentas con una excavadora.
Además, los story points sirven para medir la productividad. En un equipo de trabaja mejorando contínuamente sus habilidades, procesos y herramientas la tendencia que se debe observar es hacia el incremento de número de story points producidos por semana. Es decir, con las mismas horas de trabajo se espera que el equipo tienda a producir más valor con el paso del tiempo.
Aquí definiremos por convenio un story point cómo la unidad atómica de trabajo que no puede ser subdividida con propósitos de estimación. Grosso modo, un story point equivale a entre dos y cuatro horas de trabajo, ya que es prácticamente imposible realizar ningún cambio aunque sea algo tan trivial cómo cambiar dos líneas en un fichero de configuración en menos tiempo si se tiene en cuenta el tiempo necesario para leer y entender el cambio requerido, verificar que ha funcionado y procesar la burocracia asociada a la petición de cambio.
Luego en resumen el método de estimación de esfuerzo consiste en listar las funcionalidades de producto, para cada funcionalidad enumerar las piezas que requiere y a cada pieza asignarle una cantidad de story points. Esto es lo que hace el siguiente Excel de ejemplo:
![]()
Estimaciones de alto nivel
Al principio de todo es posible que no se pueda hacer un escandallo porque las piezas que se requerirán son aún desconocidas. En primera aproximación, una cosa que se puede hacer se conoce cómo t-shirt sizing (a mi me gusta más llamarlo cake sizing). La idea es muy sencilla: a cada funcionalidad se le asigna una categoría de complejidad a ojo de buen cubero: minúscula, muy pequeña, pequeña, mediana, grande, muy grande, enorme. Cada categoría se correlaciona con un número de story points.
El proceso de Estimación Wideband Delphi
Una forma de asignar story points a las funcionalidades es el poker planning el cual consiste en que los técnicos se reunen y literalmente apuestan cuanto esfuerzo va a requerir una funcionalidad. Este método presenta varios inconvenientes. En primer lugar no es sistemático debido a que usa juicios ad hoc en lugar de contar piezas. Además, se sabe que la estimación de uno de los técnicos puede influenciar la de los otros. Es posible que un miembro del equipo sea más respetado y por ello su opinión subjetiva tenga más peso que los juicios objetivos de otros miembros del equipo, o puede que en cuanto un miembro haya hecho una estimación los otros tiendan a llegar precipitadamente a un consenso. Por estos motivos Boehm propuso en 1981 lo que denominó Wideband Delphi Estimation Process cuya técnica es la siguiente:
1. Se selecciona un pequeño grupo de personas para hacer cada estimacion.
2. Se designa un coordinador delphi para cada estimación.
3. El coordinador pide que cada miembro haga estimaciones independientemente.
4. El coordinador recopila las estimaciones y las consolida.
5. Durante la consolidación, el coordinador puede descartar estimaciones que están claramente desencaminadas.
6. El coordinador convoca una reunión para acordar con los miembros del equipo la estimación final.
Calibrado
Debido a la incertidumbre inicial en las estimaciones y a que la estimación se genera de forma independiente de la cantidad de horas necesarias, es necesario calibrar el modelo que se use de dos formas. Primera hay que tener alguna métrica del márgen de error en las estimaciones. Esto requiere de algunas matemáticas que me voy a llevar a un apéndice para no fastidiar al lector no técnico ni a aquellos sin ganas de leer sobre principios estadísticos sobre la marcha. Y la segunda es una correspondencia entre story points y horas/hombre que debería ser actualizada en cada iteración.
Conclusión
Para producir estimaciones consistentes a través de las iteraciones se requiere un método sistemático y repetible.
Este método puede ser un proceso Wideband Delphi que produce story points asignados para cada funcionalidad.
Apéndice A: Checklist de Estimación
- ¿Está claramente definido lo que se está estimando?
- ¿Incluye la estimación todos los tipos de desarrollo necesarios para completar la funcionalidad?
- ¿Incluye la estimación todas las áreas funcionales?
- ¿Tiene en cuenta la estimación los requerimientos de seguridad, auditoría y rendimiento?
- ¿Tiene la estimación suficiente nivel de detalle cómo para no esconder ningún trabajo inesperado?
- ¿Están los miembros del equipo que tendrá que implementar de acuerdo con la estimación?
- ¿La estimación es para software nuevo o para modificar otro existente?
- ¿Se asume que la productividad será similar a aquella en otros desarrollos comparables en las mismas condiciones?
- ¿Incluye la estimación un peor caso, caso medio y peor caso?
- ¿Es el peor caso realmente lo peor que puede pasar con alguna probabilidad?
- ¿Se han documentado todos los prerrequisitos, restricciones y asunciones?
- ¿Ha cambiado el entorno desde que se hizo la estimación?
- ¿Están los recursos humanos necesarios suficientemente asignados y comprometidos?
Apéndice B: Agregados y medidas de error
Para hacer planificación de un proyecto se necesita algo más que las estimaciones individuales. También hay que poder:
1. Agregarlas.
2. Hacer un análisis PERT.
3. Estimar el márgen de error.
Ninguna de esas es trivial. No es buena idea simplemente sumar todas las estimaciones, la razón es que para cada estimación existe (o debería existir) un mejor caso, un caso medio y un peor caso; medidos en story points. Para crear un sumatorio significativo hay que tener en cuenta la desviación típica, una medida de la variación de un conjunto de datos numéricos que no tengo espacio para explicar aquí. De modo que lo voy a resumir a tope con una receta.
Para menos de diez estimaciones, lo mejor es tomar el mejor caso y el peor caso para un cálculo aproximado de la desviación típica hecho de la siguiente forma:
Desviacion Típica = (Suma de los peores casos – Suma de los mejores casos) / D
Donde D es un divisor tomado según la siguiente tabla:
| Si el esfuerzo real está dentro del rango estimado al menos un X % de las veces | Entonces tomar el dividor D cómo |
|---|---|
| 20% | 0,51 |
| 40% | 1 |
| 50% | 1,4 |
| 60% | 1,7 |
| 70% | 2,1 |
| 80% | 2,6 |
| 90% | 3,3 |
| 99% | 6 |
La desviación típica se puede utilizar para calcular la probabilidad de que el esfuerzo real sea mayor o menor que el estimado.
| Un X % de las veces | El esfuerzo real será menor o igual que |
|---|---|
| 2% | Estimación – (2 × Desviación Típica) |
| 10% | Estimación – (1,28 × Desviación Típica) |
| 16% | Estimación – (1 × Desviación Típica) |
| 20% | Estimación – (0,84 × Desviación Típica) |
| 25% | Estimación – (0,67 × Desviación Típica) |
| 30% | Estimación – (0,52 × Desviación Típica) |
| 40% | Estimación – (0,25 × Desviación Típica) |
| 50% | Estimación |
| 60% | Estimación + (0,25 × Desviación Típica) |
| 70% | Estimación + (0,52 × Desviación Típica) |
| 75% | Estimación + (0,67 × Desviación Típica) |
| 80% | Estimación + (0,84 × Desviación Típica) |
| 84% | Estimación + (1 × Desviación Típica) |
| 90% | Estimación + (1,28 × Desviación Típica) |
| 98% | Estimación + (2 × Desviación Típica) |
Las estimaciones de desviación sobre las estimaciones, sirven para introducir buffers de seguridad los cuales pueden introducirse a nivel de funcionalidad o por camino crítico de proyecto usando PERT, una técnica fuera del ámbito de este artículo.
Apéndice C: Herramientas de estimación
La lista de herramientas de estimación en Wikipedia es sorprendentemente corta y ni siquera incluye algunas herramientas relativamente conocidas cómo SystemStar. Ahsta dónde yo sé, todo el mundo que conozco usa bien algo encima de JIRA bien Excel. O algunos herramientas propias.
Apéndice D: Otros métodos de estimación
El método propuesto aquí no es para nada el único posible para estimar. De los métodos alternativos voy a citar sin explicarlos sólo tres para el lector interesado en leer más: Putman’s Software LIfecycle Management, COCOMO, y Puntos Función IFPUG. COCOMO require, a mi juicio, un nivel de madurez en la recolección y explotación de datos que la mayoría de las organizaciones simplemente no alcanzan. Respecto de los Puntos Función yo creo que están obsoletos. Los Puntos Función se inventaron para estimar el esfuerzo de procesos batch que convertían datos de entrada en datos de salida. Entonces la complejidad del proceso es bastante bien aproximada por la complejidad de las entradas y las salidas. Pero los puntos función no se inventaron originalmente para estimar el esfuerzo de interfaces de usuario complicados e interactivos cómo los que existen en la mayoría de las aplicaciones.
Post relacionado: Cómo sobrevivir a las estimaciones de software





Pingback: Cómo ponerle el precio a un producto software | La Pastilla Roja
Pingback: Plantilla de lo qué hay que pedirle a un programador cuando promete algo | La Pastilla Roja