
Hubo un tiempo en que todos los proyectos de la Fundación Apache podían encontrarse listados en su página de inicio. Hoy en día los proyectos 172 que hay en el directorio ya no les caben en la home y se encuentran listados en una página aparte. Hay tantos proyectos que es difícil aclararse, incluso siendo programador. Además los nombres de los proyectos no es que ayuden precisamente a identificarlos (Hadoop es el nombre del elefante de goma que tenía el hijo de su creador). En este post voy a comentar de forma asequible para el lector no técnico los principales productos de Apache relacionados con Big Data. No voy a entrar en generalidades conceptuales sobre Big Data, las cuales daré por sentadas o en caso contrario recomiendo el libro Big Intelligence de Antonio Miranda.
Esquemas de datos, consistencia y disponibilidad
Antes entrar en productos y tecnologías, no obstante, sí quiero hacer hincapié acerca de una diferencia fundamental entre las tecnologías relacionales clásicas y el enfoque de Big Data. Esta diferencia es si se graban los datos contra un esquema de datos ya existente (como el de una base de datos relacional) o si los datos entrantes no deben forzosamente adaptarse a priori a ningún esquema predefinido ni cumplir restricciones de integridad referencial. Cuando se impone que los datos entrantes cumplan las restricciones de un esquema se introduce una penalización en el tiempo necesario para grabarlos y, potencialmente, también una gran cantidad de bloqueos en las tablas de datos. Las operaciones de chequeo llegan a ser demasiado costosas para un sistema que recibe una enorme cantidad de datos entrantes y, por consiguiente, la solución de Big Data es simplemente diferir las comprobaciones y la normalización de datos. Adicionalmente, otra ventaja de trabajar sin esquema previo es que todos los datos entrantes se graban sin modificar a bajo coste y a largo plazo lo cual permite crear nuevas formas de explotación en caso de ser necesarias en el futuro.
El otro gran desafío de las arquitecturas distribuidas es el enunciado por el Teorema CAP que establece que en un sistema distribuido no es posible garantizar la consistencia, la disponibilidad y la tolerancia al particionado simultáneamente. Aunque existen vias de escape si se prohibe actualizar o borrar cualquier dato una vez grabado. Varios productos Big Data funcionan de hecho con esa restricción permitiendo crear nuevas versiones de una fila en una tabla o de un documento pero nunca modificar ni borrar una fila o documento anterior.
Tipos de datos que hay que almacenar y explotar
En casi cualquier aplicación de negocio o científica hay ocho tipos de datos que precisan ser almacenados y explotados. Cada uno de estos tipos de datos tiene características especiales que requieren diferentes tecnologías de almacenamiento, recuperación y explotación.
1. Imágenes y documentos (electrónicos o escaneados).
Las imágenes y documentos pueden ser muy grandes pero poco o nada se sabe normalmente acerca de su contenido. Se almacenan bien en sistemas clave-valor estilo Amazon S3 o Berkeley DB, bien en gestores documentales especializados como Jackrabbit. Para la búsqueda de imágenes y documentos en un sistema clave-valor es posible emplear un indexador “full-text” separado como Solr (la versión distribuida de Lucene). Solr tiene adaptadores que le permiten leer e indexar directamente OpenDocument y muchos otros formatos.
2. Formularios.
Los formularios son lo que los usuarios rellenan en pantalla cuando quieren registrarse en un sitio web, realizar una solicitud o publicar en Facebook. Lo que caracteriza a los formularios es que puede haber muchos diferentes que además cambian con el tiempo. Y no está para nada garantizado que los usuarios vayan a introducir información de calidad (hasta 68 formas diferentes de declarar la nacionalidad española he encontrado yo en una columna de una base de datos procedente de un campo de texto libre en un formulario). Las aplicaciones que manejan procesos por etapas casi siempre necesitan almacenar formularios a veces compartidos por distintos usuarios si se trata de procesos de negocio. Los formularios no son, en general, adecuados para una explotación directa. Por ejemplo, supongamos que se trata de un proceso de registro en una web de comercio electrónico. En el formulario de alta se le pedirán al cliente sus datos personales y una dirección de envío, todo ello en la misma pantalla. Sin embargo, la base de datos necesita almacenar los datos personales por un lado y la dirección por otro, ya que la dirección podría cambiar en el futuro y, por consiguiente, es preciso mantener un histórico de direcciones. El producto de Apache más adecuado para almacenar formularios es CouchDB. Se trata de una base de datos sin esquema que almacena documentos en formato JSON. Bueno, en realidad cada documento incluye su propio esquema (derivado de los campos JSON). CouchDB es NoSQL con replicación multimaster e interfaz CRUD a través de HTTP. Es decir, es fácil comunicarse con CouchDB desde Javascript mandando y recibiendo objetos JSON a través de HTTP. CouchDB está escrito en Erlang, lo cual no tiene absolutamente nada de malo, pero, como no es una elección habitual para el lenguaje base, también hay otra implementación 100% JavaScript que puede correr sobre Node.js
3. Entidades.
Las entidades son con lo que trabajan las bases de datos relacionales clásicas: persona, compañía, empleado, dirección, etc. Las entidades se almacenan en tablas y, para ser eficaces, deben evitar la duplicidad de datos (esto se conoce como normalización) y mantener integridad referencial entre ellas (la provincia en una dirección debe existir en una tabla de provincias y pertenecer al pais elegido). En Apache se puede encontrar una base datos relacional llamada Derby, pero es sólo para sistemas empotrados con baja huella de memoria o fines de testeo. Casi todo el mundo usa MySQL o PostgreSQL como base de datos relacional en producción.
Merece la pena hacer una mención aparte para las entidades que representan productos de un catálogo pues son un caso muy particular debido a que cada producto puede tener un conjunto de muy atributos diferentes, por ejemplo una cámara digital versus un jersey. Además, para cada producto puede haber variantes en tallas y colores. Hay básicamente cuatro posibilidades para almacenar los atributos de los productos: 1ª) se pueden almacenar en una tabla relacional atributo-valor (lo cual es ineficiente), 2ª) se pueden almacenar en una base de datos orientada a columna (de las cuales hablaremos luego), 3ª) se pueden almacenar en un campo BLOB o CLOB de la base de datos relacional, o quizá algo más sofisticado como un HStore de PostgreSQL, 4ª) se puede usar una base de datos sin esquema como CouchDB y permitir que cada producto lleve su propio conjunto de atributos.
Otro caso de uso muy típico es el almacenamiento de entidades con relaciones jerárquicas (donde una entidad contiene otras). Este desafío técnico a mi me parece curioso porque aunque las primeras bases de datos empezaron siendo jerárquicas, como IMS, el modelo relacional simplemente no es adecuado directamente para almacenar jerarquías. Los dos métodos comunes para almacenar jerarquías en bases de datos relacionales son la lista de adyacencia y los conjuntos anidados en cuyos detalles técnicos no voy a entrar pero puede encontrarse una buena explicación aquí. Debido a que los árboles son un tipo de grafo, es posible utilizar eficientemente una base de datos de grafos para almacenar jerarquías, lo cual veremos a continuación.
4. Grafos.
Almacenar un grafo en una base de datos relacional no es realmente nada difícil. Solo se necesita una tabla de nodos y otra de vértices. En SQL para un grafo dirigido :
CREATE TABLE nodos (
id INTEGER,
CONTRAINT pk_nodos PRIMERY KEY(id)
)
CREATE TABLE vertices (
id_nodo_inicio INTEGER,
id_nodo_fin INTEGER
)
El problema de esta implementación es que para obtener la lista de nodos sucesores de uno dado hay que hacer:
SELECT id_nodo_fin FROM vertices WHERE id_nodo_inicio=?
Lo cual parece trivial pero hay que tener en cuenta que incluso estando la tabla vertices bien indizada esta consulta se ejecutará en un tiempo que será log(n) siendo n el número de filas en la tabla vertices. Entonces si el grafo es grande se sobrecargará rápidamente la base de datos.
Lo que hace esencialmente una base de datos orientada de grafos es almacenar los sucesores de cada nodo pegados al propio nodo de manera que el tiempo de recuperación de los sucesores de un nodo permanezca siempre constante independientemente del crecimiento en tamaño del grafo.
Puede ser conveniente separar el almacenamiento de la explotación de grafos. Una posibilidad es almacenar los grafos en tablas como las ejemplificadas y precargarlos enteros en memoria para explotarlos. Esto es lo que hace Apache Giraph. Los nodos y vértices se almacenan en Hadoop pero el grafo se carga en la memoria de los nodos de un cluster. El modelo de programación de Giraph sigue el Pregel de Google. Giraph es la herramienta que Facebook utiliza para analizar el grafo de sus usuarios.
Titan, otra herramienta de procesamiento de grafos, no es de Apache pero hace uso de Cassandra o de HBase para almacenar los grafos. La diferencia práctica con Giraph es que Giraph está más orientado a OLAP y Titan a OLTP.
Además de los sistemas de almacenamiento, en Apache se pueden encontrar otros dos toolkits con algoritmos sobre grafos: Tinkerpop y Spark GraphX.
5. Series temporales.
Las series temporales expresan como cambia una variable función del tiempo. Un ejemplo sencillo son las predicciones meteorológicas por localidad. La primera dificultad para almacenar y tratar series temporales es que el modelo entidad-relación no incluye ninguna noción de temporalidad. Supongamos que tenemos una tabla de empleados y otra de empresas. Entonces en una base de datos relacional es trivial crear una clave foránea desde empleados a empresas que garantice que la empresa referenciada siempre existira. Pero no existe ninguna forma directa de expresar que el empleado Fulanito de Tal trabajó para Cual empresa entre 1994 y 1999. Hay que crear una tabla de histórico de empleos donde el sistema gestor de bases de datos relacional tampoco garantiza que no se solapen los empleos.
Para el caso concreto de las series temporales como las meteorológicas es posible emplear una base de datos orientada a columna como Cassandra. En una base de datos orientada a columna cada fila puede contener un número diferente de columnas y, además una cantidad muy grande de ellas, entonces es posible utilizar el nombre de la localidad como clave de la fila y crear una columna cuyo nombre sea de de cada instante del tiempo en el cual se tomó una medición y la celda contenga el valor de la medición.
6. Logs.
Los logs son toda la actividad que hay que grabar por cuestiones de auditoría de seguridad, trazabilidad de usuarios o depuración del sistema. La moda para recopilar logs es Kafka un sistema distribuido escrito en Scala que prioriza el rendimiento sobre la garantía de grabación de los logs en caso de fallo. Los logs son fáciles de recopilar cuando se trabaja con una sóla máquina. Simplemente hace falta un archivo y una cola de escritura asíncrona. Apache Tomcat trae de serie un recopilador de logs asíncrono que puede activarse fácilmente. El problema con los logs aparece cuando se pretende combinar los procedentes de varios servidores, especialmente si se desea que estén grabados en un orden estricto (usualmente temporal). Lo que Kafka hace es encolar localmente en cada servidor los mensajes de log, y luego los publica en un cluster al cual los procesos que extraen información de los logs pueden suscribirse.
6. Eventos.
En ocasiones es necesario que la aplicación reaccione en un tiempo corto como respuesta a un evento externo. O que sea capaz de aceptar una avalancha de eventos externos. Para la recolección de eventos es posible usar Apache Flume. Y para el procesamiento en tiempo casi real es posible usar Flink o Storm.
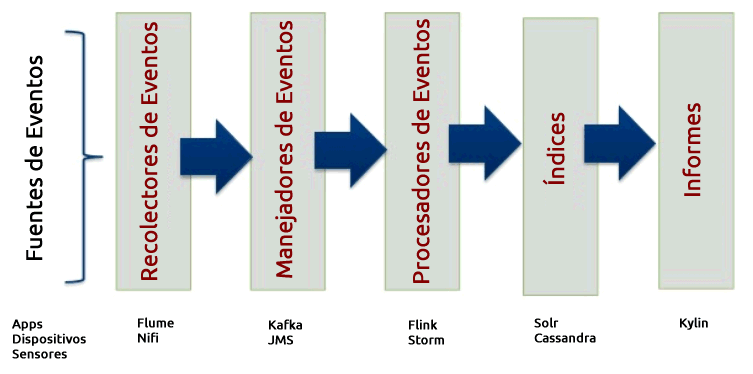
8. Informes.
Los informes son normalmente de tres tipos: 1º) listados operativos (transferencias bancarias realizadas ayer), 2º) resúmenes de KPIs (Key Performance Indicator), 3º) resultados OLAP (OnLine Analytical Processing) para modelos predictivos, simulación, etc.
La creación de informes consta de dos etapas. Primero se hace un proceso de extracción, transformación y carga (ETL) en el cual se leen los datos del almacén NoSQL y se graban en otro almacén apropiado, típicamente cubos OLAP para el análisis multidimensional. El proceso ETL puede ser bastante costoso y complicado computacionalmente motivo por el cual requiere un análisis refinado de los tiempos necesarios para mover los datos teniendo en cuenta la velocidad de la electrónica de red y de los discos. El proyecto de Apache para hacer OLAP sobre Hadoop es Kylin donado por eBay.
Principales productos big data en Apache
Hadoop
Las plataforma base de almacenamiento distribuido en Apache es Hadoop, un sistema distribuido de archivos.
La forma más sencilla de entender conceptualmente Hadoop es pensar que es como un disco virtual que por detrás está compuesto realmente de montones de discos esparcidos por un cluster de servidores. Las tecnologías de virtualización hacen que una misma máquina física pueda ejecutar varias máquinas virtuales. Pues bien, Hadoop hace exactamente lo contrario: muestra varias máquinas físicas como una única máquina virtual.
El sistema de archivos de Haddop se conoce como HDFS. Por razones técnicas, HDFS no maneja bien archivos pequeños. El espacio minimo que un archivo HDFS ocupa se suele fijar en una cantidad entre 64Mb y 256Mb. HDFS permite crear, eliminar, leer secuencialmente y añadir datos a archivos, pero no se puede modificar el contenido de un archivo excepto copiándolo en local y subiendo a HDFS una nueva copia.
Hadoop también incluye un ejecutor de procesos llamado YARN (Yet Another Resource Negotiator). YARN se diseñó originalmente para ejecutar MapReduce pero luego evolucionó hacia la ejecución de procesos en general proporcionando facilidades para que los procesos ejecutados se encuentren lo más próximos posibles a los datos, a ser posible en la misma máquina o si no al menos en el mismo rack.
La principal pega del API de Hadoop es que originalmente sólo funcionaba con Java y, además, carece de abstracciones para representar otros objetos que no sean sus «archivos ballena».
Al igual que sucede con las distros de Linux, es posible utilizar directamente el software de Hadoop disponible en la web de Apache, pero muchos clientes utilizan una distribución comercial con soporte y software adicional bajo licencia principalmente porque configurar y mantenar operativo un cluster de Hadoop no es para nada sencillo técnicamente. La distribución con mayor cuota de mercado es Cloudera, seguida de HortonWorks, MapR, Amazon Elastic MapReduce e IBM Infosphere BigInsights.
HBase
HBase es una base de datos maestro-esclavo orientada a columna implementada sobre Hadoop siguiendo el modelo de Google Bigtable. En HBase cada fila en una tabla debe tener una clave primaria. En principio, no existen índices secundarios, de modo que en esencia se trata de un sistema clave-valor pero con algunos «extras» importantes.
Cada tabla en HBase se compone de un conjunto de familias de columnas. Las familias de columnas deben definirse de forma estática cuando se crea la tabla pero luego cada fila puede contener un número diferente de columnas en cada familia de cada fila. Todas las columnas de una familia se almacenan juntas y ordenadas por nombre. Además, pueden existir múltiples versiones para los valores de cada celda, ordenados según una marca temporal (timestamp). El calificativo de tabla en las bases de datos orientadas a columna es, por consiguiente, equívoco, ya que sugiere algo similar a una tabla relacional o a una hoja Excel cuando en realidad consiste en una estructura distribuida de datos que dada una clave devuelve una colección de mapas (familias) nombre-valor.
Volviendo al caso de almacenamiento de grafos, recordemos que el problema de almacenarlos en una base de datos relacional es que para encontrar los sucesores de cada nodo es preciso realizar una consulta en una tabla cuyo tiempo de ejecución depende del tamaño del grafo y del número de sucesores. En HBase (u otra base de datos orientada a columna como Cassandra) los sucesores pueden obtenerse eficientemente como todas las columnas de una familia en una fila recuperada por clave primaria (el identificador del nodo de origen). Debido a que todas las columnas de una familia se almacenan juntas, los sucesores de un nodo pueden recuperarse en una única operación en lugar de tener que escanear la tabla con las relaciones nodo-origen – nodo-destino.
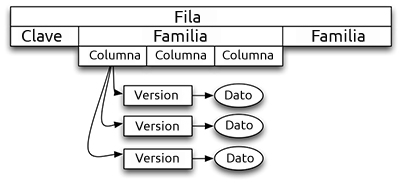
A diferencia de las bases de datos relacionales, HBase no permite especificar claves foráneas, tampoco existen índices secundarios ni se pueden definir transacciones. Las operaciones de lectura y escritura son atómicas a nivel de fila pero HBase carece de un mecanismo para garantizar que dos filas serán actualizadas de forma coherente. Los índices secundarios pueden crearse mediante una funcionalidad llamada coprocesadores, que también sirve para emular disparadores y procedimientos almacenados, pero programar contra el API de los coprocesadores no es fácil. Las transacciones y el soporte SQL pueden montarse por encima con otro proyecto de Apache llamado Phoenix. No obstante, el uso de Phoenix implica una penalización en rendimiento y escalabilidad ya que hay que añadir un gestor centralizado de transacciones a un sistema cuya escalabilidad depende de que funcione de forma distribuida. Además, yo creo que el uso de SQL es innecesario y equívoco en el caso de las bases de datos orientadas a columna.
HBase almacena los datos ordenados por clave primaria, por tanto, ofrece un redimiento óptimo para recuperar datos por rango de valores de la clave primaria. Un ejemplo podría ser el almacenamiento de emails siendo la clave primaria un identificador de usuario seguido de una marca temporal, y dos familias de columnas, una para las cabeceras y otra para el cuerpo del mensaje. Esto permitiría recuperar eficientemente los últimos n mensajes de cada usuario. Los índices secundarios, no obstante, habría que montarlos manualmente por separado.
HBase proporciona interfaces Java y Thrift y también un shell JRuby.
Hive y Pig
Para superar las limitaciones funcionales de Hadoop en el tratamiento de datos aparecieron Hive y Pig. Hive lo que permite básicamente es tratar archivos de texto un dialecto de SQL (HQL) como si fuesen tablas de una base de datos relacional, pero sin precargar los datos en un SGBDR. El esquema de los archivos tratados se almacena como metadatos en una base de datos relacional auxiliar. Esto permite hacer operaciones como count() o sum() y también join de archivos pero sin pagar el coste del tiempo de carga en un SGBDR.
Pig es principalmente una herramienta de ETL. A diferencia de Hive, funciona sin esquema y consta de tres partes: 1ª) Pig Latin, un lenguaje de scripting para describir procesos MapReduce; 2ª) Grunt, un shell interactivo y 3ª) Piggybank, un repositorio de funciones definidas por el usuario (UDF).
Hive y Pig están siendo paulatinamente desplazados por Spark.
Spark
Spark ha sido de un tiempo a esta parte la estrella de las aplicaciones de Apache para Big Data. Es un desarrollo originario del AMPLab de UC Berkeley que fue donado a Apache. Su éxito se basa en una mayor orientación a hacer uso intensivo de la memoria por contraposición a Hadoop que está orientado a usar los discos y en su aproximación de programación funcional sobre dos abstracciones de datos conocidas como resilient distributed data set (RDD) y DataFrames. Los RDD básicamente tablas distribuidas e inmutables sobre las que se pueden realizar dos tipos de operaciones: transformación y acción. La transformación convierte el RDD en otro RDD. Por ejemplo, map, filter, flatMap, groupByKey, reduceByKey, aggregateByKey, pipe, y coalesce son transformaciones. Y algunas acciones son reduce, collect, count, first, take, countByKey, y foreach. Spark evalua las transformaciones y acciones de forma perezosa, es decir, los resultados no se calculan realmente hasta que un proceso trata realmente de consumirlos para hacer uso de ellos. A diferencia de Hadoop donde las etapas map y reduce de MapReduce se comunican a través del disco, Spark intenta comunicar los resultados entre etapas en memoria motivo por el cual puede alcanzar rendimientos de uno o más órdenes de magnitud superiores a Hadoop.
Spark requiere para funcionar de un gestor de cluster y de un sistema de almacenamiento persistente. El gestor de cluster puede ser uno nativo de Spark, o también YARN o Apache Mesos. Para el almacenamiento Spark puede usar HDFS, MapR-FS, Cassandra, OpenStack Swift, Amazon S3 o Kudu.
Spark se compone de cinco modulos: core, SQL, streaming, machine learning (MLib) y grafos (GraphX). El core proporciona las funcionalidades de procesamiento y almacenamiento distribuido a través de interfaces Java, Scala, Python y R.
Cassandra
Cassandra es otra base de datos orientada a columna. Originalmente desarrollada por Facebook y luego donada a Apache. No es maestro-esclavo como HBase sino que se compone de un conjunto de nodos iguales que se comunican por un protocolo P2P sin depender de Hadoop como HBase. La estructura de las tablas es similar a la de HBase aunque se permite que los valores de las celdas sean también mapas atributo-valor. Y se pueden crear índices secundarios sobre columnas que no contengan mapas en sus celdas. Es decir, se puede pensar en una fila de Cassandra como un conjunto de mapas anidados.
En general, los benchmarks tienden a mostrar que Cassandra muestra un buen comportamiento respecto de los tiempos de escritura, pero las latencias son mayores que las de HBase en los tiempos de lectura. Ambas base de datos manejan las escrituras grabando previamente cada petición en un log local que luego se graba en el nodo o nodos apropiados del cluster como un sistema de mezcla coordinada de logs.
Cassandra ofrece APIs Java, C#, Python y Thrift. Pero el interfaz Thrift está siendo descatalogado en favor de CQL sobre JDBC.
Machine Learning
Hay tres proyectos en Apache que incluyen algoritmos de machine learning: Spark MLib, Mahout y FlinkML. Mahout proporciona un motor genérico de álgebra pero a la postre se trata la mayoría de las veces de encontrar el proyecto que contiene el algoritmo de machine learning requerido.
Otros proyectos Apache
Para no abrumar al lector, me he dejado en el tintero al menos dos docenas de proyectos de Apache. Hay una lista descriptiva aqui.
Consejos para elegir y desplegar tecnologías big data
1. Hacer un inventario de tipos de datos que se vayan a necesitar.
2. Definir los patrones de acceso a los datos.
3. Crear los modelos de datos de acuerdo a las necesidades de los patrones de lectura y escritura.
4. Utilizar el menor número posible de productos y tecnologías diferentes pues cada pieza añade complejidad adicional y aumenta la probabilidad de fallo del sistema.
5. No obstante lo anterior, no almacenar nunca en una base de datos relacional ni los logs ni los archivos binarios grandes. Las razones para no hacerlo son: 1ª) la escritura constante de logs puede sobrecargar fácilmente el sistema gestor de base de datos y 2ª) los logs y los archivos binarios grandes crecerán rápidamente hasta representar la mayor parte del tamaño de la base de datos, eso dificultará los backups y creará problemas de espacio en disco que no existirían si los logs y los archivos se guardasen separadamente en otro lugar más apropiado.
6. Elegir los proveedores para cada tecnología seleccionada. Aquí entran en juego detalles técnicos que dependen de las necesidades de cada proyecto. No se puede decir que PostgreSQL sea mejor que MySQL o que Cassandra sea mejor que HBase. Tampoco es inmediato que una infraestructura cloud proporcionada por un tercero sea mejor que una infraestructura propia. Depende de para qué.
7. Estimar el coste de despliegue y de mantenimiento. Mantener operativo un cluster, en general, no es fácil ni barato.
8. Establecer las métricas de coste de almacenamiento y retorno de inversión por byte almacenado. En función de dichas métricas, decidir qué datos merece la pena conservar y por cuánto tiempo.
9. Verificar cómo se moverán los datos de una plataforma a otra.
10. No confiar aspectos críticos del negocio a nuevas tecnologías hasta que no se haya comprobado su estabilidad. No todo lo que se puede descargar de Apache es estable. En el caso de las bases de datos los mayores problemas casi siempre se encuentran en los drivers de la parte cliente. El servidor en si mismo es estable. Pero el driver pierde memoria, o un mal uso del mismo deja conexiones abiertas que acaban tumbando el servidor. Si se monta una base de datos relacional para las entidades, y Cassandra para almacenar el catálogo de productos, y un cluster de Hadoop para el almacenamiento de imágenes, y HBase para almacenar mensajes de los clientes, y CouchDB para almacenar los formularios de las encuestas de satisfacción y Flume para capturar eventos y Kafka para gestionar los logs y Spark para hacer análisis de los datos y Kylin para hacer OLAP y… y… y… Muy probablemente el sistema será escalable hasta el infinito al tiempo que por completo inestable e imposible de mantener.
Posts relacionados:
NoSQL para no programadores.
El ecosistema de productos Big Data.
Cómo diseñar una aplicación escalable.




