
Recientemente se celebró el AI Safety Summit sponsorizado por el Gobierno Británico para la seguridad en el uso de Inteligencia Artificial. En encuentro sigue a la cumbre AI for Good organizada por la ONU en Ginebra en julio de 2023.
El lugar escogido para AI Safety Summit fue Bletchley Park, una mansión victoriana en la localidad de Milton Keines a unos 80 Km al noroeste de Londres. El lugar posee interés histórico por ser donde Alan Turing consiguió descifrar el código Enigma alemán usado en la II Guerra Mundial. También simboliza el concepto que los organizadores tienen sobre la inteligencia artificial, es decir, algo secreto e indescifrable con gran potencial de uso militar.
Mucha charlatanería y pocas conclusiones concretas en las cumbres internacionales, por supuesto. Excepto que los ingleses pretenden llegar a una legislación de compromiso que no sea el descontrol total del que gozan las empresas de Silicon Valley ni tampoco el afán regulatorio extremo de la Unión Europea que nos lleve a que tras el aviso de las cookies todo website tenga que poner otro aviso diciendo que las estadísticas de navegación y compra del usuario se procesan con algoritmos de inteligencia artificial.
La preocupación principal es que la inteligencia artificial se empiece a usar para generar una realidad informativa alternativa hecha a la medida de los intereses de su creador. Lo que está cambiando es que, hasta ahora, cada buena mentira necesitaba estar basada en una media verdad. Desde hace décadas, es posible cambiar por completo la figura de una persona en una imagen, incluso hacerla desaparecer. Pero se necesita empezar con una foto real. Si es un anuncio de perfumes, la modelo debe existir, si es una foto de boda, alguien tenía que estarse casando aquel día. Pero, de un tiempo a esta parte, ya están apareciendo videos de líderes mundiales pronunciando discursos que realmente nunca existieron y escenas totalmente ficticias sin pizca de veracidad.
Hasta ahora, el peligro era la desinformación. Bien por censura, bien por manipulación sesgada de las noticias. A partir de ahora, el peligro será la aparición de una narrativa totalmente falsa. Me refiero no sólo a fotografías falsas, sino a que la inteligencia artificial se está sofisticando para redactar noticias falsas que parezcan creíbles y, además, conectarlas de tal manera que una parezca la causa/efecto de la otra induciendo al lector a saltar a conclusiones erróneas.
La primera consecuencia es que es bastante probable que la sociedad se polarice en dos frentes: el de aquellos que sólo creen las noticias que confirman sus prejuicios y el de aquellos que ya no se creen absolutamente nada por abrumadoramente evidente que parezca. Esto equivale a pendular entre la acción irracional violenta y el marasmo de no movilizarse nunca por nada sin importar lo catastrófica que se anuncie la situación.
Al creciente peligro del uso malicioso de la inteligencia artificial hay que sumarle el fenómeno de la concentración de los medios de comunicación. En EE.UU. una docena de empresas controlan el 90% de todos los medios de comunicación. Y no les gusta que aparezcan opiniones discrepantes. Un buen ejemplo reciente de ello es el escándalo brutal que se montó en los medios de comunicación cuando Elon Musk compró Twitter y decidió ir por libre. Según los medios, Twitter (ahora X) pasó de ser la herramienta de difusión de la verdad en países oprimidos a ser, según los otros medios, la mayor fuente planetaria de noticias falsas, quizá porque Elon Musk decidió, entre otras muchas cosas, restituirle la cuenta a Donald Trump.

La inteligencia artificial y la concentración de medios forman un dúo fatídico porque la generación de contenidos con inteligencia artificial requiere de una gran cantidad de recursos computacionales. Incluso para jugar en casa con los modelos de generación de texto más rudimentarios (estilo ChatGPT) se requiere una inversión de varias decenas de miles de euros en hardware especializado. Por consiguiente, sólo aquellos que tienen mucho dinero poseen la capacidad de generar contenidos falsos difícilmente distinguibles de los reales.
Los mismos que están alertando sobre los peligros de la inteligencia artificial son quienes están haciendo ya un mayor uso de ella con fines de manipulación informativa.
La propaganda tal y cómo la recibimos hoy en día la inventaron los ingleses durante la I Guerra Mundial y la perfeccionaron los alemanes durante el ascenso al poder del nazismo. Con respecto a la propaganda, prácticamente nada nuevo se ha inventado conceptualmente desde principios del Siglo XX.
Los principios fundamentales de la propaganda son los siguientes:
- Apelar siempre a las emociones de la audiencia antes que a su intelecto.
- Empezar con algo que sea parcialmente cierto.
- Escoger un mensaje sencillo, si es posible, simplificarlo hasta el simbolismo como la esvástica, la hoz y el martillo o la Z pintada en los blindados rusos desplegados en Ucrania.
- Repetir el mensaje machaconamente saturando todos los canales posibles: periódicos, panfletos, mítines, manifestaciones, películas de cine, redes sociales, etc. Bajo la premisa de que cualquier mentira se puede convertir en verdad si se repite suficientes veces.
- No mencionar simultáneamente más de cuatro o cinco temas como máximo cada día.
- Sesgar las noticias de manera que no se diga expresamente cual es la moraleja, sino falsificando pruebas para que el receptor llegue a la conclusión deseada por sus propios medios, ya que tenemos tendencia conceder mayor veracidad a lo que creemos que hemos descubierto antes que a lo que nos han dicho cómo cierto.
- Crear un sentimiento de grupo tribal entre quienes comparten la versión oficial de la historia.
- Presentar a todos los que se oponen al mensaje cómo enemigos públicos.
- Acorralar, marginar o, si es preciso, eliminar a cualquier pensador independiente que quede.
- Cuando se agote el mensaje cambiarlo por otro, puede ser incluso lo contrario si se espera algún tiempo. La audiencia tiene poca o nula memoria histórica.
Todo esto nos resulta familiar ¿verdad? ¿Cómo podemos pues empezar a dudar de nuestras propias creencias? Una forma de hacerlo es usar la técnica que usan los museos para verificar la autenticidad de un cuadro. Es bastante difícil saber si un cuadro es una obra original que vale millones o sólo un plagio muy bien hecho con el mismo valor comercial que un póster publicitario. Lo que hacen los museos es preguntar sobre la historia del cuadro: su proveniencia y documentación. ¿Cuándo se pintó? ¿Quién fue el primer propietario? ¿A quién se vendió? ¿Qué materiales y soporte usa?
Se puede crear una imagen digital de la nada. Pero si existe un negativo fotográfico procedente de una cámara de 35mm que llevaba un reportero en una fecha y lugar, eso es imposible de falsificar. A menos, claro está, que fuese el propio fotógrafo quien puso ahí todo lo que sale en la foto. A muchos les han pillado con imágenes de cadáveres trasladados desde otra parte o artefactos movidos de sitio.
Los avisos sobre los peligros de la inteligencia artificial son una operación de falsa bandera. La manipulación de medios más sofisticada procede de la socialdemocracia.
Existe el mito de que la propaganda rusa está por todas partes y es la mano negra de todo, incluyendo la manipulación de intención de voto electoral. La propaganda rusa existe en gran cantidad, sin duda. No obstante, a mi juicio, la propaganda rusa es sorprendentemente mala. La razón es que los propagandistas rusos siguen pensando en ruso incluso cuando publican mensajes destinados a una audiencia global. Son mensajes propagandísticos que funcionan en Rusia, con rusos, pero no en otras partes del mundo, lo mismo que en Arabia no se promociona el jamón Jabugo ni en Extremadura se anuncian latas de arroz con curry. La mejor forma de comprobarlo es leer la versión en inglés de TASS, la agencia oficial de noticias del Kremlin. La estrategia de TASS es simple: empezar con un suceso real, tergiversar las cifras y repetir el mismo mensaje todos los días. Las noticias pretenden aportar datos muy concretos para darles apariencia de veracidad: exactamente cuántos soldados ucranianos fueron abatidos, cuántos blindados, en qué lugar, qué batallón, con qué medios. Lo que sucede es que es difícil creer que realmente mataron anteayer a 137 soldados ucranianos de la unidad 102ⁿᵈ, a 2,5Km del pueblo de Morozova Dolina en la región de Kharkov. Además, destruyeron, dos blindados Bradley, cuatro camiones y un howitzer M777. En una guerra donde el 70% de las bajas son causadas por fuego lejano de artillería ¿Cómo pueden determinar siempre con tanta exactitud las pérdidas enemigas? Luego el mensaje se repite día tras día, sin mencionar pérdidas propias.
Otra forma de hacerlo es la del sitio de noticias “open source” Oryx. Según Oryx, las pérdidas materiales rusas triplican a las ucranianas. Eso lo soportan con una gran cantidad de fotos recopiladas en Internet, todas ellas dificilísimas o imposibles de falsificar. El problema de Oryx, en mi opinión, es que los ucranianos y los rusos comparten una gran cantidad de material de la era soviética. Entonces hay ocasiones en las que no se puede saber de qué bando era el tanque destruido que sale en la foto.
Si los rusos son malos propagandistas, los ucranianos son aún más torpes. Encabezados por el Kyiv Post, sus redactores parece que no hayan ido nunca ni a la escuela de periodismo. Hablan de que han interceptado una llamada de un soldado ruso a su madre para decirle que llevan semanas sin llevarles comida al frente. Cuentan que los rusos ejecutan a sus propias tropas o las obligan a cargar colina arriba contra fuego de mortero. Pero las noticias no aportan absolutamente ninguna evidencia de nada de lo que se cuenta en ellas. Los rusos dan cifras falsas y sólo de pérdidas del bando contrario. Los ucranianos, directamente, no informan nunca de ninguna cifra.
En una ocasión los ucranianos usaron una foto procedente de Siria alegando que se trataba de la destrucción de material ruso desde un dron Bayraktar TB2 donado por Turquía.

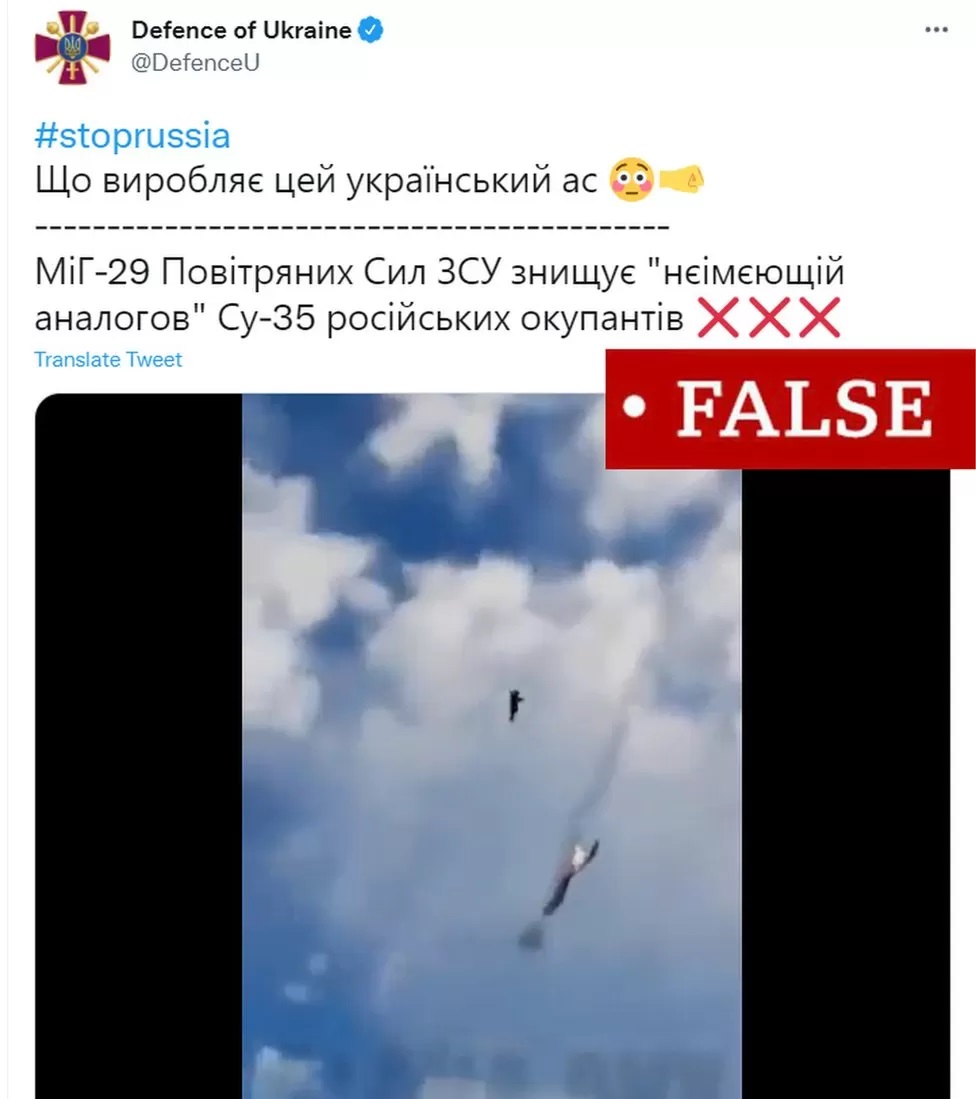
También publicaron una foto de un MiG-29 ucraniano presuntamente derribando un SU-35 ruso y se descubrió que la imagen procedía del videojuego Digital Combat Simulator World. Al piloto conocido cómo Fantasma de Kiev se le atribuyeron 6 victorias aéreas en 30 horas (con su MiG-29) más de las que Tom Cruise logró en toda su carrera Top Gun.
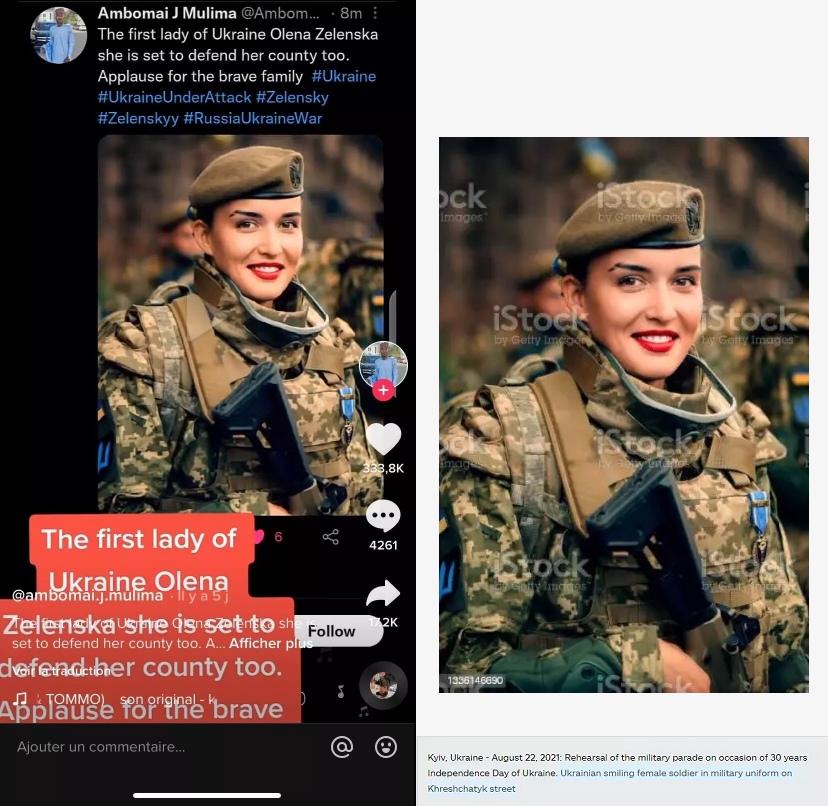
Los ucranianos publicaron una foto de la presunta mujer de Zelensky vestida de militar que en realidad se había subido al banco de imágenes iStock en 2021.
Una de las imágenes que, para mi sorpresa, no usan los ucranianos, son los tanques “descabezados”. Conocido cómo el “efecto jack-of-the-box” (por la caja de juguete de la cabeza con un muelle). Se produce cuando un proyectil penetra el blindaje de un tanque y hace estallar la munición que lleva provocando que explote desde dentro y liberando la presión por la parte más débil que es la junta entre el casco inferior y la torreta. Los tanques T-80 son especialmente vulnerables a esto ya que llevan un cargador automático. Los Challenger 2, en teoría, llevan la munición protegida en compartimentos con agua, pero el Challenger 2 que fue alcanzado por un misil 9M133 Kornet también voló por los aires de la misma forma y murieron todos los tripulantes. Supongo que tales imágenes podrían provocar que la opinión pública empezase a sentirse en contra de enviar Javelin y otros misiles que pueden destruir cualquier tanque de esa forma.

Una fuente alternativa de noticias es Al Jazeera. Propiedad del Gobierno de Qatar, Al Jazeera es anti-israelí, anti-rusa y anti-republicana, con un claro sesgo en favor de los demócratas estadounidenses pero aún en contra de la permisividad que han mostrado, y siguen mostrando los demócratas estadounidenses con las atrocidades de guerra cometidas por Israel. Es por eso que la última foto del secretario de estado estadounidense Antony Blinken ha sido al lado de la bandera de Qatar.

Los que sí saben hacer propaganda y manipular la verdad son los que nos alimentan de noticias en los países occidentales. En nombre de la libertad y de la democracia, los gobiernos de Europa y EE.UU. llevan décadas ayudando a sus aliados a masacrar a sus opositores. Habría remontarse a las peores matanzas nazi de la II Guerra Mundial o al genocidio camboyano 1975-1979 para encontrar otros casos en los que la población civil haya sido tan sistemáticamente perseguida con fines de exterminio mientras todo el mundo mira hacia otra parte fingiendo que está haciendo algo por detener acciones que van en contra de los derechos humanos y de las normas de la guerra. Incluyendo, por cierto, sacar a chavales de 18 años del instituto para enviarles forzosamente al frente, cómo si su vida no valiese nada en comparación con la de los civiles.
Se ha creado una narrativa de «buenos» y «malos». Quién es el «bueno» y quien es el «malo» depende del bando que uno quiera (o le dejen) elegir. La abrumadora cantidad de información que existe en Internet es inútil para conocer con objetividad lo que está pasando, ni siquiera los servicios secretos los saben. Nos hemos ido todos a vivir a una ficción alternativa al mundo real.
Un 27% de la población mundial y un 60% de todos los territorios están bajo sanciones económicas de la UE o EE.UU. La UE ha dictado por ahora 1.784 sanciones económicas contra individuos y empresas rusas y congelado activos por valor de 350.000 millones de euros. La presión económica constante para mantener a una buena parte de la población en la pobreza también es una forma de violencia. La estrategia incluso tiene nombre: se conoce cómo «patear la escalera por la que subiste» para impedir que ningún otro país se desarrolle económicamente de igual manera que lo lo logró uno mismo.
En resumen, ahora más que nunca debemos juzgar críticamente todas las noticias que nos lleguen. Preguntarnos ¿cual es la fuente? ¿cual es la historia completa? ¿se corresponde el fondo con el frente de la imagen? ¿cómo es la luz? ¿estoy creyendo en esto porque parece real o sólo porque es lo que quiero creer?





 El 27 de noviembre de 2019 se presentó una
El 27 de noviembre de 2019 se presentó una 



 e teorías conspiranóicas, pero me pregunto cuántos lectores saben que Naciones Unidas, en colaboración con el Banco Mundial, tiene un ambicioso plan para proporcionar identidad biométrica a todo habitante del planeta en 2030. Comentaré los detalles más adelante. Pero cómo entradilla, quiero plantear la siguiente reflexión: ¿Qué se necesita para instaurar un totalitarismo? La respuesta es controlar siete cosas:
e teorías conspiranóicas, pero me pregunto cuántos lectores saben que Naciones Unidas, en colaboración con el Banco Mundial, tiene un ambicioso plan para proporcionar identidad biométrica a todo habitante del planeta en 2030. Comentaré los detalles más adelante. Pero cómo entradilla, quiero plantear la siguiente reflexión: ¿Qué se necesita para instaurar un totalitarismo? La respuesta es controlar siete cosas: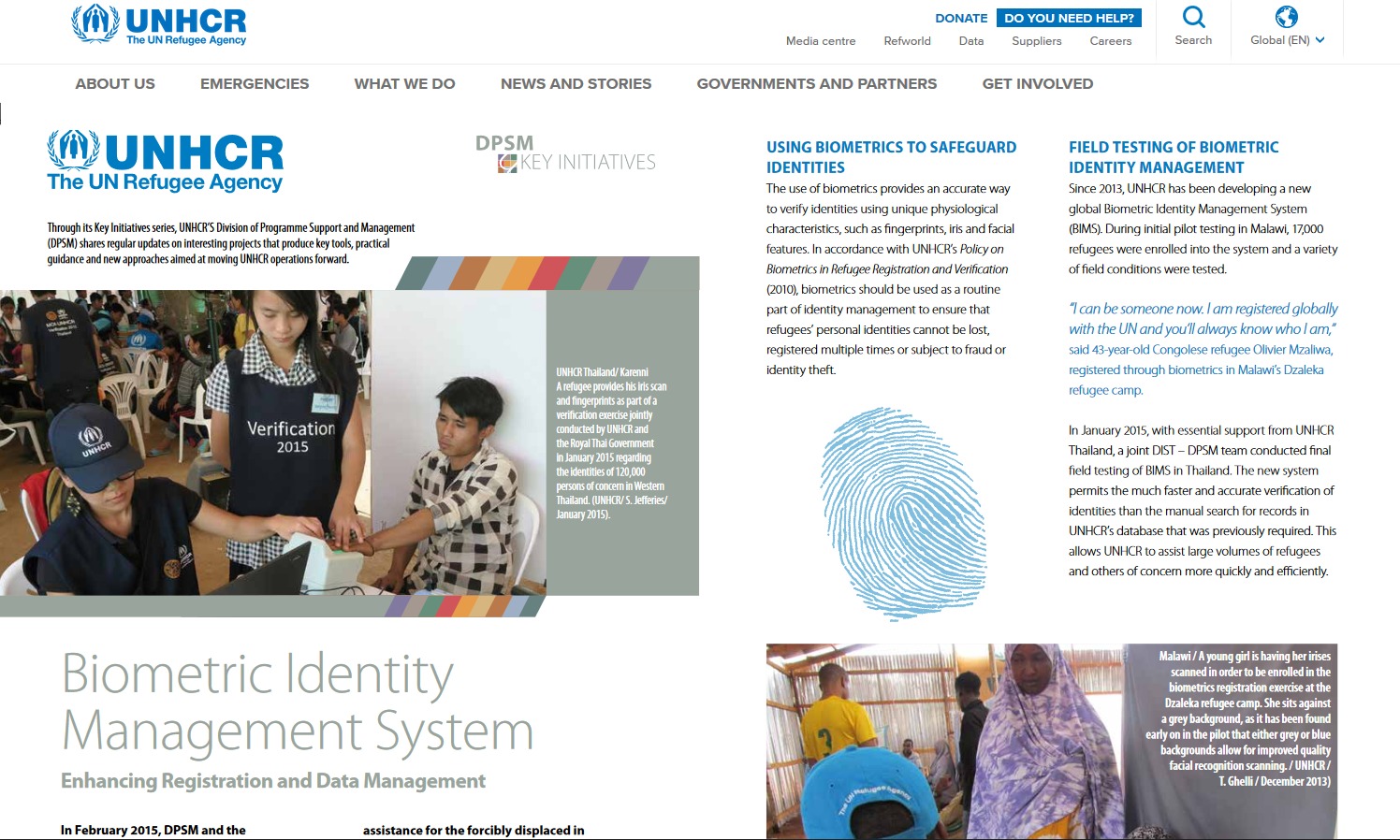

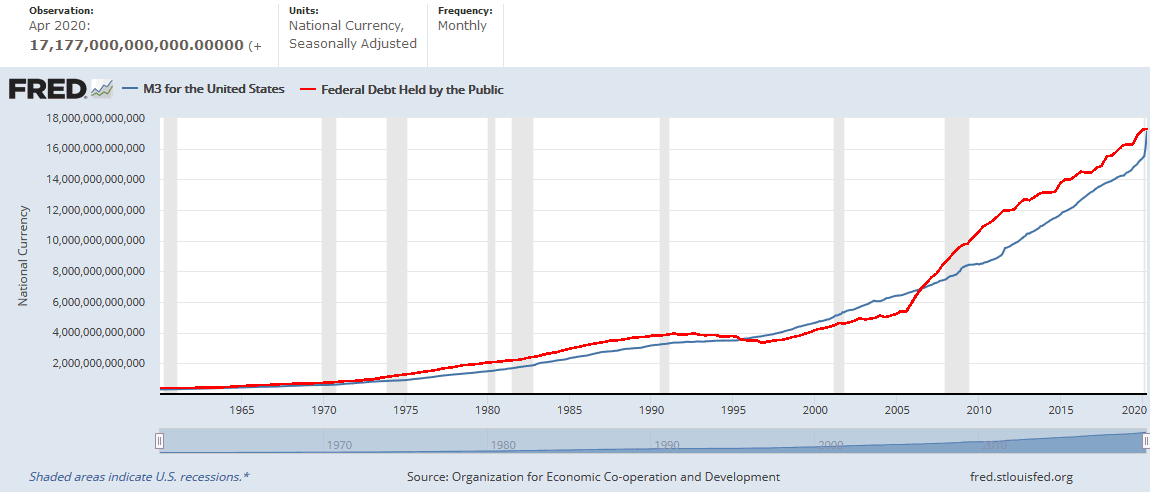 Fuente: FRED
Fuente: FRED  Conozco no pocas personas quienes opinan que la sociedad y las nuevas tecnologías nos están volviendo tontos. Siempre he visto a estos escépticos del progreso cómo
Conozco no pocas personas quienes opinan que la sociedad y las nuevas tecnologías nos están volviendo tontos. Siempre he visto a estos escépticos del progreso cómo 