
Iba a escribir un post sobre Google Knowledge Vault como continuación del que escribí sobre Watson y Wolfram Language pero me he dado cuenta de que sólo con la introducción que dí al científico de datos es muy difícil entender los fundamentos que hay detrás de recientemente renovado interés por el aprendizaje automático. De modo que voy a hacer un receso con fines didácticos para el que le interesen los fundamentos sobre cómo aprenden las máquinas. Existen centenares de algoritmos, algunos bastante complejos. Aquí sólo hago un repaso sobre los principios elementales de los métodos más simples y populares.
Percepción
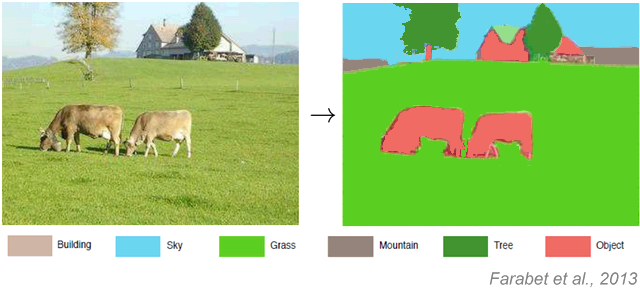
La percepción es la organización, identificación e interpretación de información sensorial con el propósito de representar y entender el entorno. Veamos un ejemplo sencillo sobre algo que se puede enseñar a una máquina a que identifique en una fotografía de forma muy parecida a cómo lo hace Facebook.
Aprendizaje
Lo que se entiende por aprendizaje en el contexto que nos ocupa es el hallazgo de una función h(x) —llamada frecuentemente hipótesis— que dado un vector de entrada x proporcione una estimación lo bastante buena de otra cantidad relacionada con x. Por ejemplo, para una casa sea x = (metros construidos, dormitorios, baños, planta, código postal, fecha de construcción, fecha de última reforma) y el valor que h(x) debe aproximar lo mejor posible es el precio de mercado p.
El entrenamiento se realizará de forma progresiva refinando progresivamente la función hipótesis mediante otra función de coste que en el ejemplo del precio de las casas podría ser un cálculo de mínimo error cuadrático. Si tenemos n transacciones de compra-venta para las que se conocen las características de las casas y el precio real p de la operación el error cuadrático será:
Es decir, se trata de encontrar la función de hipótesis que hace mínimo el valor de la función coste, idealmente cero, si se pudiese predecir con total exactitud el precio de compra-venta.
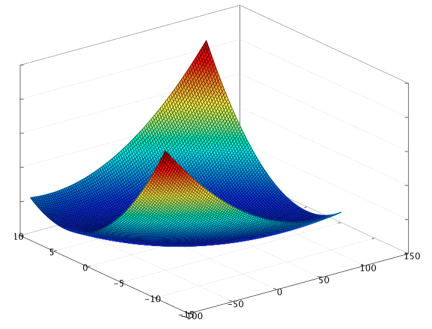
La búsqueda del mínimo para la función coste se lleva a cabo mediante un método conocido como descenso del gradiente en cuyos detalles técnicos no voy a entrar pero, que visualmente, consiste en encontrar el punto más bajo de la superficie que en siguiente gráfico representaría el valor de la función coste para una función hipótesis con dos parámetros escalares de entrada.
Tipos de aprendizaje automático
Todo el mundo lo llama machine learning, abreviadamente ML, de manera que me referiré a él en lo sucesivo como ML. Hay dos tipos principales de ML: aprendizaje supervisado, y aprendizaje no supervisado con varios subtipos.
El aprendizaje supervisado consiste, por ejemplo, en proporcionarle a la máquina dos conjuntos de imágenes etiquetadas perro y gato. Entonces la máquina debe encontrar una función que aplicada a una nueva imagen clasifique si es un perro o un gato.
La recompensa por la señal supervisada puede ser diferida. Por ejemplo, para el caso de aprender a encontrar la salida a un laberinto. Esto se conoce como reinforcement learning (RL). En el caso más general de RL incluso se desconoce la forma del mundo sobre el que se trabaja (la forma del laberinto). Esto acarrea la necesidad de elegir estratégicamente sobre cuánto tiempo se emplea desvelando la forma del laberinto y cuánto tiempo se emplea aplicando lo que se sabe sobre cómo salir de él (compromiso entre exploración y explotación).
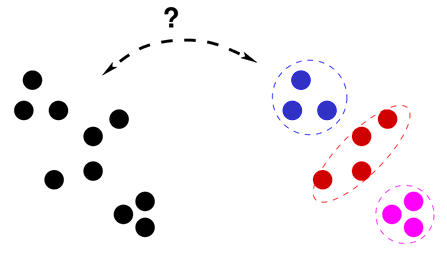
En el aprendizaje no supervisado no se suministran categorías inicialmente a la máquina. No es una tarea de clasificación sino de organización para descubrir la estructura de los datos para visualizarlos o comprimirlos mejor. Examinando la estructura hallada por la máquina es cómo se extraen los conceptos, abstracciones, factores, etcétera. que explican el significado de los datos.
Expresado de otra forma, en el aprendizaje supervisado existe un conjunto de variables X1, X2, …, Xn y la misión es predecir el valor de otra variable Y. En el aprendizaje no supervisado se trata de encontrar patrones en el conjunto de valores posibles para X1, X2, …, Xn.
Existen dos grandes subtipos de aprendizaje supervisado: regresión, en el cual el valor predicho cae dentro de un rango (estilo ¿cuánto tiempo? ¿cuántas unidades?) o clasificación (estilo ¿es el tumor canceroso?).
A su vez, el aprendizaje no supervisado puede dividirse en dos subtipos: el clustering, que es esencialmente organizar los datos en grupos, y los algoritmos que persiguen proyectar los datos en un espacio de dimensión inferior y en este último caso las dimensiones deben interpretarse como factores semánticos.
Es posible que se necesiten aprender varias tareas simultáneamente. En el más famoso concurso de ML hasta la fecha, el premio del millón de dólares de Netflix al mejor recomendador de películas, lo óptimo es poder contar con las opiniones que cada usuario ha realizado sobre las películas que ha visto, y comparar dichas opiniones con las de otros usuarios para averiguar qué le gustará ver. Pero, por otra parte, existen usuarios recién llegados quienes no han publicado ningún rating. A estos usuarios por supuesto también se desea ofrecerles alguna recomendación por otro medio que no sea cotejar opiniones. Por consiguiente, se necesita alguna forma estadística de encontrar su similitud con otros usuarios. Evidentemente, ambas tareas están relacionadas. El truco para conseguir mejores modelos con ambas es no compartir demasiado ni demasiado poco entre ellas, lo cual depende de cuántos datos se disponga y cuánto conocimiento previo para el ajuste fino de cada tarea. Esto se conoce como multi-task learning.
Modelos paramétricos vs. no paramétricos
Los modelos paramétricos son aquellos que asumen que los datos de entrada se distribuyen con una probabilidad que puede ser descrita mediante un conjunto de parámetros. En los modelos no paramétricos la complejidad de su espacio de hipótesis crece según lo hace el número de instancias de datos a considerar y no se puede «comprimir» en un conjunto de parámetros.
Los modelos paramétricos, en general, son computacionalmente más eficientes que los no paramétricos. También pueden ser predictivamente mejores si las hipótesis ad hoc sobre la distribución de los datos son correctas. Pero si las hipótesis son falsas, la capacidad predictiva resulta seriamente mermada por lo cual lo modelos paramétricos son menos robustos que los no paramétricos.
k-NN
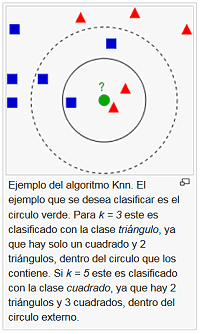 k-NN es el acrónimo de k Nearest Neighbors classifier. Es el método más simple no paramétrico de aprendizaje supervisado. Los datos de entrada tienen la forma {Xin, Yn} donde Xin es el valor del atributo i para el caso n e Yn es la etiqueta a la que debe adscribirse ese caso. También se necesita una métrica de similitud entre casos (distancia) d(Xm, Xn) donde, por convenio, generalmente a mayor d mayor similitud. La clasificación es sencilla, para cada nuevo caso Xp se calcula la distancia d(Xp, Xn) para todo caso en el conjunto de datos y se toman los k casos más similares. A continuación se toman las etiquetas de esos casos y se asigna al nuevo caso la etiqueta más popular entre sus vecinos. k-NN sufre lo que se conoce como “la maldición de las altas dimensiones”. Es posible que al introducir nuevas variables se deteriore la capacidad predictiva del algoritmo, por consiguiente, se necesitan técnicas para elegir las características relevantes que podrían ser objeto un artículo entero en si mismas.
k-NN es el acrónimo de k Nearest Neighbors classifier. Es el método más simple no paramétrico de aprendizaje supervisado. Los datos de entrada tienen la forma {Xin, Yn} donde Xin es el valor del atributo i para el caso n e Yn es la etiqueta a la que debe adscribirse ese caso. También se necesita una métrica de similitud entre casos (distancia) d(Xm, Xn) donde, por convenio, generalmente a mayor d mayor similitud. La clasificación es sencilla, para cada nuevo caso Xp se calcula la distancia d(Xp, Xn) para todo caso en el conjunto de datos y se toman los k casos más similares. A continuación se toman las etiquetas de esos casos y se asigna al nuevo caso la etiqueta más popular entre sus vecinos. k-NN sufre lo que se conoce como “la maldición de las altas dimensiones”. Es posible que al introducir nuevas variables se deteriore la capacidad predictiva del algoritmo, por consiguiente, se necesitan técnicas para elegir las características relevantes que podrían ser objeto un artículo entero en si mismas.
Naive Bayesian
Naive Bayesian es la técnica empleada habitualmente por los filtros antispam. Consiste en crear una serie de reglas con una probabilidad asociada a cada una. Por ejemplo, si el título del mensaje contiene la palabra «Viagra» entonces tiene un 80% de probabilidades de ser spam. Las reglas pueden votar a favor o en contra de que el correo sea spam. Se considera que las probabilidades son independientes unas de otras (de ahí el adjetivo naive) aunque se pueden crear reglas combinadas estilo «si contiene la palabra Viagra y las palabras farmacia online».
El clasificador bayesiano se puede entrenar progresivamente para mejorar sus resultados. No voy a poner aquí las matemáticas de cómo se hace, pero la idea intuitivamente es sencilla: las probabilidades inicialmente se estiman contando cuántos correos en el juego de entrenamiento son spam y qué reglas cumple cada uno; luego, dado un nuevo correo, el operador humano lo clasifica como spam o no spam. Entonces la máquina recalcula las probabilidades para las reglas teniendo en cuenta la nueva información proporcionada por el operador.
Hay otros detalles relevantes para que el clasificador bayesiano funcione bien. En particular, la regularización, que tiene que ver con cómo evitar que el peso de una regla sea superior al de todas las otras juntas. Y los umbrales de «presunción de inocencia» para no declarar spam correos que no tengan realmente una probabilidad muy alta de serlo.
Máquinas de Soporte Vectorial
En inglés support vector machines (SVMs). Se trata de otro conjunto de algoritmos de clasificación lineal con aprendizaje supervisado alternativos a las redes de neuronas formadas por perceptrones. Como en el caso de las redes de neuronas, se trata de encontar un hiperplano que separe dos clases de objetos. Las SVMs son el ejemplo más popular de los métodos kernel.
En el caso de que las clases sean linealmente separables, para hallar el hiperplano que las separa se toman un conjunto de casos, llamados vectores de soporte (en el gráfico v1 y v2) y se elige el hiperplano que proporcione los mayores márgenes de distancia desde el hiperplano a los vectores de soporte más próximos. En el ejemplo, tanto el plano z1 como z2 podrían servir para distinguir las clases, pero z2 es mejor porque el margen es más amplio.
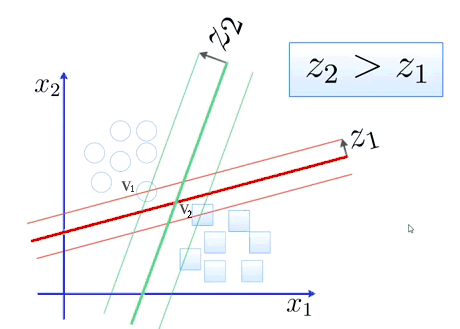
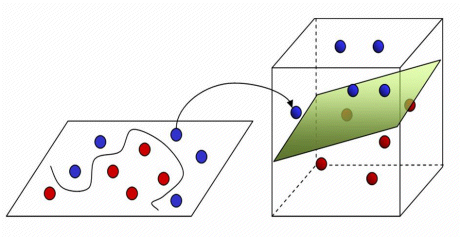
En el caso de que las clases no sean linealmente separables lo que se intenta hacer es proyectar los casos a un espacio de dimensión superior donde sí sean linealmente separables.
El perceptrón
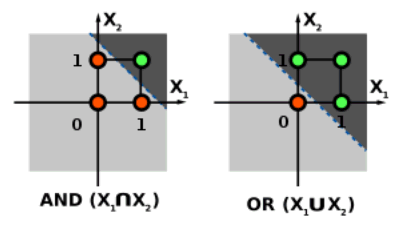
El perceptrón es la neurona artificial. El perceptrón funciona como un discriminador lineal. Es una variante de aprendizaje supervisado para clasificación binaria. La forma más fácil de entender el concepto es mediante un dibujo. Veamos la representación en un plano de las funcionas booleanas AND y OR.
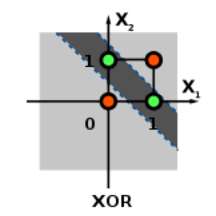
El perceptrón de una capa sólo puede distinguir las funciones si sus resultados pueden separarse mediante una recta. Si los patrones no son linealmente separables (como en el caso de la función XOR) entonces hay que emplear redes de neuronas multicapa con funciones de activación no lineales.
Las redes multicapa tiene una capa de entrada una capa de salida y una o más capas intermedias. La capa de entrada tiene tantos perceptrones como dimensiones tenga el vector que representa el caso a clasificar. Las capas de neuronas se conectan hacia delante mediante «pesos» ajustables. Cada neurona de cada capa está conectada con todas las neuronas de la siguiente aunque las conexiones se pueden desactivar asignando un peso cero al enlace. El aprendizaje en el caso de las redes neuronales consiste en encontrar el peso correcto para cada neurona.
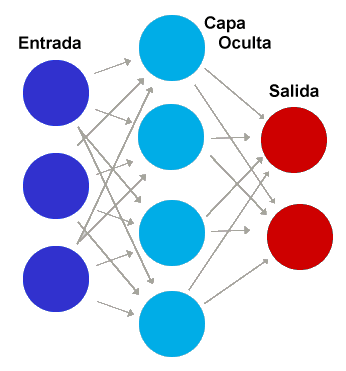
Aunque se introduzcan capas intermedias, si los perceptrones usan funciones de activación que sean lineales, entonces la salida siempre será una funcion lineal de la entrada (dado que cualquier combinación de funciones lineales es otra función lineal). Por ello, casi todas las redes de neuronas usan funciones de activación no lineales para los perceptrones: logística, hiperbólica, escalón, base radial, gaussiana, etc.
Los perceptrones multicapa no lineales se pueden usar como aproximadores universales para cualquier función. Es decir, dada una función que devuelve valores aleatorios a partir de las entradas, es posible entrenar una red multicapa de perceptrones que produzca una buena aproximación. O, expresado de otra forma, se puede implementar cualquier algoritmo con una red multicapa lo bastante lo bastante grande.
Redes de neuronas artificiales
FFN: El tipo más simple de red neural es la feedforward en la que la información fluye en una única dirección, desde la capa de entrada a la de salida a través de las capas ocultas. No hay caminos cíclicos entre las conexiones. Con frecuencia se usan la sigmoide o softmax como funciones de activación. Las feedforward utilizan como método de aprendizaje supervisado la retropropagación (backpropagation). Para cada salida se calcula la diferencia entre la respuesta correcta y la obtenida y se reajustan hacia atrás los pesos de los perceptrones de manera que el reajuste minimice el error buscando el mínimo mediante una variante del método del gradiente presentado con anterioridad conocida como descenso del gradiente incremental (o estocástico) en el cual los pesos se actualizan después de considerar cada ejemplo de entrenamiento en lugar de esperar a considerarlos todos. El gradiente de la función coste h(x,y) en un punto (x, y) es un vector que sale del punto y sus componentes son las derivadas parciales de la función en dicho punto. grad(h) = ∇h = (∂h/∂x,∂h/∂y) Una pega de la retropropagación es que es posible que existan mínimos locales del gradiente donde el aprendizaje se quede atascado sin encontrar el mínimo global.
Autocodificadores: Los autocodificadores (autoencoders) son otro subtipo de feedforward de tres capas que se usa como componente en deep learning.
CNN: Las redes neuronales convolucionales (convolutional neural networks) son otro subtipo de feedforward utilizado para el reconocimiento y clasificación de imágenes. Las CNN simulan cómo funciona la corteza visual primaria (V1) de un cerebro biológico. En las CNN cada neurona de una capa no recibe conexiones entrantes de todas las neuronas de la capa anterior, sino sólo de algunas.
RBF: Las redes de base radial (radial basis function) tienen siempre tres capas: entrada, oculta y salida y producen una salida que calcula la distancia de la entrada a un punto elegido como centro. La salida es una combinación lineal de las funciones de activación radiales utilizadas por las neuronas individuales. Una ventaja de las RBF es no presentan mínimos locales donde la retropropagación pueda quedarse encallada como en las feedforward de perceptrones multicapa.
RNN: En las redes neuronales recurrentes (recurrent neural networks) las neuronas pueden estar conectadas hacia adelante o hacia atrás. Puede que la conexión bidireccional esté limitada a neuronas de capas consecutivas (SRN simple recurrent networks) o que no exista ninguna restricción hasta el punto de que todas las neuronas estén conectadas con todas, aunque las redes con interconexión total se han demostrado hasta la fecha inútiles para fines prácticos. Las SRN de tres capas se conocen también como redes Elman. Las SRN tienen como ventajas sobre las feedforward que para una salida objetivo dada con un margen de error la Elman puede converger más rápido hacia el coste mínimo que la feedforward. Es decir, el número de de iteraciones que los datos de entrenamiento y posteriormente los datos de prueba deben realizar dentro de la red es menor. El porcentaje de efectividad de las Elman también es mejor debido a que los caminos de retroalimentación generan un mejor comportamiento no-lineal durante el aprendizaje supervisado. Sin embargo, estas ventajas tienen un impacto elevado en el tiempo de
procesamiento necesario.
Otro subtipo importante de RNN es Máquina de Boltzmann inventada por Hinton y Sejnowski en 1985. En 1986 Paul Smolensky introdujo la máquina de Boltzmann restringida (RBM). La RBM tiene tres capas en la que cada neurona de una capa puede estar conectada bidireccionalmente con las neuronas siguiente capa, pero no existen conexiones entre las neuronas de la misma capa.
Deep Learning
Deep Learning es la etiqueta para un conjunto de algoritmos que habitualmente se emplean para el entrenamiento no supervisado de redes de neuronas multicapa.
Desde que hace aproximadamente una década Hinton y Salakhutdinov descubrieron un algoritmo eficiente para entrenar un tipo de redes de neuronas multicapa conocida como deep belief nets, se ha producido un avance espectacular en el reconocimiento de imágenes, escritura manual, lenguaje hablado y traducción automática.
La popularidad del deep learning se basa en que el método conocido como descenso por gradiente estocástico (SGD) puede entrenar eficazmente redes neuronales de entre 10 y 20 capas para resolver problemas que ocurren en la práctica. Lo cual es relevante porque el reajuste de pesos en una red neuronal a partir de los errores es un problema de optimización no convexa NP-Completo.
Voy a dejar esta introducción (incompleta) aquí. A quien le queden fuerzas para seguir leyendo, la explicación continúa de forma muy asequible en el post ¿Qué es y cómo funciona “Deep Learning”? de Rubén López.
Artículos relacionados:
A Tour of Machine Learning Algorithms (Jason Brownlee)
http://elpais.com/elpais/2015/12/10/ciencia/1449736542_882081.html (Miguel Ángel Criado)





Pingback: De la inteligencia artesanal a la inteligencia industrial | La Pastilla Roja
Pingback: El boom de los asistentes de voz y sus implicaciones | La Pastilla Roja