
En un momento de la historia apareció La Nube ¡Rayos! ¿Por qué los informáticos no pueden llamar a las cosas por su nombre? ¿Por qué no pueden llamarlo «lavandería compartida»: ese sitio donde todos vamos a lavar nuestros trapos sucios en un maquinorcio que no nos cabe en la casa?
Muchas veces alguien me ha pedido que interprete lo que le está diciendo el informático, veamos si en esta ocasión soy capaz de interpretar un poco eso de La Nube.
En resumen, son cinco los pilares que debes establecer:
1. Despliegue Software
2. Infraestructura Hardware
3. Conectividad
4. Políticas de protección y recuperación
5. Monitorización
En función de cómo sientes las bases de lo anterior, cinco indicadores variarán:
1. Seguridad
2. Escalabilidad
3. Disponibilidad
4. Latencia
5. Mantenibilidad
Despliegue de Software I: Fase Prototipo
Antes de elegir una infraestructura hardware necesitas saber qué es lo que vas a querer desplegar. Necesitas una lista de todos los componentes, e, importante, la versión exacta de cada uno. No es suficiente con especificar «Python, Django y Postgres». Si no especificas las versiones pronto tendrás que reinstalar algo o te encontrarás con un buen lio de compatibilidad.
Puedes empezar de forma fácil instalando con Bitnami. A mi me gusta tener el mayor grado de control sobre lo que instalo, compilando yo mismo desde fuentes y esas cosas… pero para empezar rápidamente Bitnami es a mi juicio la mejor opción.
Para el software y librerías privados se necesita un sistema de gestión de dependencias y un repositorio de control de versiones.
Para gestionar las dependencias en Java casi todo el mundo usaba Maven y últimamente la moda es migrar a Gradle. En Python manda pip.
El paradigma de control de versiones ha cambiado de Subversion a Git.
La diferencia fundamental es que Subversion es un repositorio centralizado diseñado para que los programadores no se pisen los cambios entre ellos desincentivando que trabajen en paralelo sobre el mismo módulo de código. Mientras que Git es un sistema distribuido que fomenta crear ramas (branches) y luego fusionar el trabajo (merge). Git se inventó porque los equipos de desarrollo grandes y geográficamente distribuidos llegaron a los límites prácticos de Subversion.
Pero para un equipo pequeño a mi el modelo de Git Flow me ha causado más quebraderos de cabeza que beneficios porque es más difícil que los programadores entiendan y sigan Git Flow que Subversion y porque los merges a veces causan desastres en el código que no son nada aparentes a primera vista. No obstante, la inercia de Git es tan grande que ni siquiera voy a recomendar ninguna otra cosa. El repositorio Git se puede montar en un servidor propio o en un SaaS como Github o Bitbucket.
Ni en broma pongas un sistema en producción sin un sistema de gestión de dependencias y otro de control de versiones. Y no hagas un merge seguido de una release sin cerciorarte de que no se ha perdido nada en el código.
Despliegue de Software II: Fase Mínimo Producto Viable
Una vez que tienes una «demo jugable» en un portátil hay que compartirla con todos los desarrolladores (ya sean plantilla o subcontratistas).
Todos los desarrolladores deben trabajar exactamente con el mismo entorno, porque de lo contrario se produce el efecto «en mi PC funciona» (pero en el servidor de producción no).
Mi forma favorita de sincronizar a los desarrolladores es crear una máquina virtual con Vagrant para VirtualBox o VMWare.
Vagrant permite especificar cómo se instala una máquina desde cero en un paquete distribuible que ocupa menos de diez megas.
Para que la máquina se instale cien por cien de forma desatendida (incluso con Vagrant) todavía se necesitan un buen puñado de scripts bash que no son nada fáciles de escribir.
No pongas un sistema en producción sin un procedimiento 100% automatizado y repetible para reinstalar cada máquina y desplegar en ella el software necesario.
Despliegue de Software III: Ampliación de capacidad
Cuando se supera la decena de máquinas es conveniente empezar a utilizar un sistema como Puppet que permita gestionar de forma centralizada lo que tiene instalado cada máquina. Puppet sirve para reemplazar a los script bash de instalación hechos a mano, pero, además, permite gestionar qué está instalado en cada máquina desde un Puppet Master. Puppet intenta reducir la dificultad de los scripts bash de instalación, pero lo hace cambiando bash por otro sistema propietario de definición de paquetes que a mi no me acaba de convencer.
Tanto Vagrant como Puppet están pensados para distribuir el software base, no el aplicativo en sí mismo (aunque también se puede usar para eso). Para la distribución de aplicativos en un pool de máquinas mi herramienta favorita es Docker. Docker hace uso de una funcionalidad en el kernel de Linux que permite aislar los recursos de un proceso de todos los demás. Es una especie de máquina virtual ultraligera. La idea es que cada pieza necesaria sea un contenedor Docker y que, disponiendo de varias máquinas, se le pueda decir a Docker: mira aquí tengo estos paquetes por un lado, y estas máquinas por otro, coge los paquetes y haz esta explotación de la máquinas.
El problema inadvertido que tienen estas herramientas es que crear una nueva máquina virtual se vuelve tan sencillo que fácilmente se produce una proliferación de ellas y a más máquinas virtuales mayor coste de mantenimiento. Crea un protocolo que dificulte la creación de una máquina virtual lo suficiente como para evitar acabar teniendo más de las necesarias.
Infraestructura Hardware
Hay cuatro opciones: servidores dedicados, servidores virtuales, cloud privado y cloud público. Y dentro de cada opción puedes elegir administrarlo tú o pagar un servicio de administración. Lo óptimo depende de cual sea el volumen de datos y los tiempos de respuesta que requeridos, pero adelantaré un consejo: antes de elegir una plataforma con cualquier tipo de virtualización haz un benchmark pues es la única manera de estar seguro de lo que tienes realmente por debajo.
Las reglas del dedo gordo son las siguientes:
1. Si tienes un pequeño negocio online, con menos de 100 pedidos o menos de 10.000 visitas al día entonces contrata un servidor virtual administrado con LAMP o Django.
2. Si los tiempos de respuesta de tu aplicación a cada transacción deben ser muy breves, o si necesitas recibir gran cantidad de datos entrantes, entonces contrata un cloud privado estilo Stackops o Stackscale.
3. Si necesitas escalabilidad y puedes repercutir tus costes variables a los clientes, entonces contrata un servicio público como Amazon, Rackspace o HP Cloud.
4. Si el volumen de datos es grande y, al mismo tiempo, los tiempos de respuesta deben ser cortos y/o tu tráfico crece antes que tus ingresos, entonces monta un sistema híbrido de cloud privado con apoyo adicional de cloud público y gestiónalo todo con una herramienta tipo ECmanaged.
Comparativa de clouds públicos
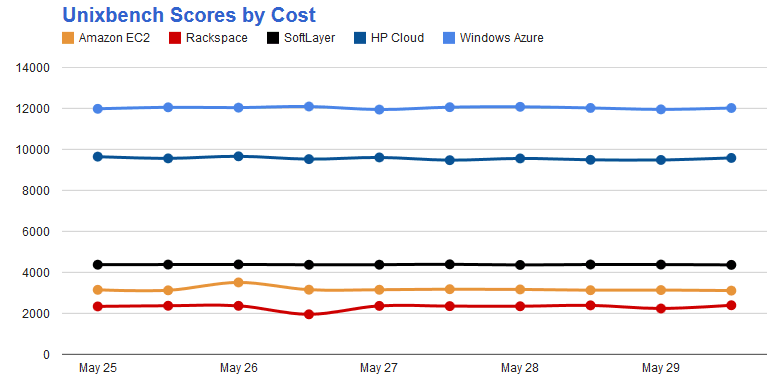
Mi experiencia con los servicios cloud públicos es que los factores críticos son las latencias de acceso a disco y el ancho de banda de subida. La siguiente tabla es cómo puntúa UnixBench con una única copia de los tests corriendo en paralelo sobre una máquina con dos CPUs en varios servicios en comparación con un VM Vagrant en mi portatil con dos procesadores i5 asignados, 3Gb de RAM y un disco duro del 7.200 rpm. Aunque he intentado escoger las máquinas virtuales que más se parecen en el pliego de contratación, instancias con dos CPUs y 4Gb de RAM, hay que tener en cuenta que es una comparación de churras con merinas.
| Proveedor | Puntuación Global | Velocidad Disco | Download/Upload |
|---|---|---|---|
| Vagrant en local | 135 | 102Mb/s | |
| Amazon EC2 m1.large | 346 | 40Mb/s | 360 / 826 Mbps |
| Google CE n1-standard-1 | 2145 | 104Mb/s | 789 / 62 Mbps |
| Azure Medium | 714 | 14Mb/s | 380 / 37 Mbps |
| Rackspace Cloud | 373 | 210Mb/s | 897 / 51 Mbps |
Globalmente Google es el servicio cloud que mejor puntúa en UnixBench y, además, obtiene una buena puntuación tanto en CPU como en I/O a disco y
ancho de banda. Rackspace parece contar con un cache SSD, el cual puede hacerlo el más rápido en lectura pero no tanto en ejecución de bases de datos. Otros benchmarks como SPEC pueden arrojar resultados diferentes en el posicionamiento de los clouds públicos y, según este otro, las instancias de 512Mb de Rackspace son mucho mejores que las micro de Amazon para ejecutar PHP.
Otra métrica interesante es comparar los resultados de UnixBench con su coste (a mayor puntuación, menor coste).
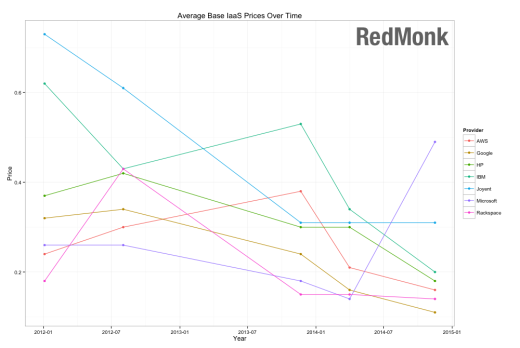
Y finalmente observar cómo están convergiendo los precios en todas las plataformas IaaS:
Conectividad
La calidad de la conectividad depende de dos parámetros, la latencia (de red) y el ancho de banda.
La latencia es una función de la cantidad de nodos de red que los paquetes tengan que cruzar desde el cliente hasta el servidor y, en menor medida, de la longuitud del cable por el que la información viaja casi a la velocidad de la luz. Por consiguiente, la mejor forma de reducir la latencia es simplemente colocar los servidores lo más próximos posibles a donde se encuentren los clientes.
El ancho de banda lo proporciona el proveedor. Para optimizarlo se puede montar una red de entrega de contenidos. La optimización de ancho de banda para dispositivos móviles y para aplicaciones de video streaming presenta dificultades adicionales más allá del ámbito de este artículo.
Políticas de protección y recuperación
Sobre los backups ya he escrito en otro artículo titulado Cómo prevenir y recuperarse de una pérdida de datos.
En cuanto a la seguridad, cinco cosas básicas:
1. Si tienes un servidor al cual se puede acceder con un par usuario/contraseña de estilo pedrito/manzanita99 eso es en la práctica lo mismo que tenerlo abierto para que el hacker más torpe del mundo entre y haga lo que quiera.
2. Los servicios de administración deben ser accesibles sólo mediante una VPN desde determinadas direcciones IP.
3. La máquina que ejecute la base de datos sólo debe ser accesible desde la red interna y sólo a través de determinados puertos desde el servidor web.
4. Ningún servidor es seguro si no ha pasado una auditoría de seguridad, las cuales suelen ser bastante costosas.
5. La mayoría de las brechas de seguridad son bien ataques perpetrados desde dentro bien robos de contraseñas que los administradores dejaron expuestas imprudentemente.
Monitorización
La monitorización de un sistema en producción debe incluir:
1. La disponibilidad de la máquina.
2. Los recursos disponibles en la máquina.
3. Los logs del servidor web.
4. La realización (o no) de transacciones.
La monitorización más básica consiste simplementen en verificar cada pocos minutos que el servidor está operativo. Que el DNS resuelve el dominio en la IP del servidor y que éste responde a peticiones HTTP por el puerto 80 en un tiempo razonable. Esto puede conseguirse con un simple wget contra unas pocas páginas diseñadas para indicar el pulso vital del sistema.
Para monitorizar los recursos lo más común es Cacti o Nagios.
Los logs deben analizarse para dos funciones completamente diferentes: la analítica con una herramienta tipo AWStats y la alerta de excepciones con otra herramienta tipo Sentry. Los logs del servidor web deben alertar inmediatamente cuando se esté produciendo un ataque por denegación de servicio o cuando se produzca una excepción inesperada (Error 500).
La monitorización de transacciones es la parte que requiere un mayor trabajo a medida. Si dejan de producirse transacciones de compra durante un tiempo es posible que la pasarela de pagos esté caída. Si, por el contrario, las ventas se disparan inesperadamente puede que los precios estén mal y la web ande regalando chollos a los visitantes, y más difíciles aún son de detectar las compras fraudulentas lo cual suele requerir de productos especializados bastante caros.
Administradores de Sistemas
Por último, se necesita un buen administrador de sistemas para gestionar todo lo anterior, ahora está de moda que los programadores hagan devops. En mi opinión eso está bien para sistemas pequeños y medianos, pero un programador tiene competencias diferentes de un administrador de sistemas y de un especialista en seguridad. En Madrid, nosotros trabajamos con Adminia hasta 2013 y la experiencia en general era buena.





Pingback: Computación distribuida con Docker y Mesos | La Pastilla Roja