
PricewaterhouseCoopers ha publicado un instructivo informe de tendencias en Big Data en el cual se comentan algunas de las tecnologías claramente emergentes como Hadoop y MongoDB y otras que yo al menos no tenía en el radar, como Clojure y Thrift.
Hay al menos tres buenos motivos que indican que el Big Data será pronto una tendencia muy fuerte en las empresas.
1º) Hasta hace poco, las empresas no podían analizar sus datos históricos porque no los tenían informatizados. El hardware necesario era demasiado caro y el software demasiado rudimentario. La era de informatización de datos empresariales se inició realmente en el año 2000.
2º) La demostración práctica por parte de Google de que MapReduce es un algoritmo paralelizable altamente eficaz para triturar gran cantidad de datos ha proporcionado un caso de éxito sólido y tangible en el que basarse. A diferencia de otras tendencias que no acaban de emerger porque no se sabe bien cómo ponerlas operativamente en práctica, en el caso del Big Data existe un conjunto de métodos y herramientas claramente usables.
3º) Debido a la globalización y al incremento de la velocidad y complejidad de los negocios, las empresas necesitarán más y mejores herramientas de análisis para la toma de decisiones que sean capaces de tener en cuenta una gran cantidad de datos de dentro y de fuera de la organización (Open Data).
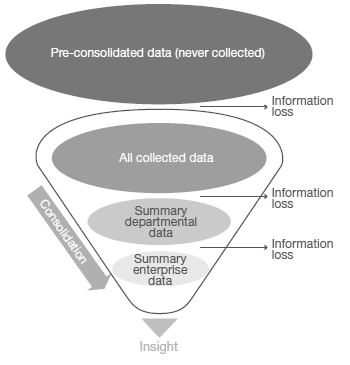 Creo que vale la pena detenerse especialmente a reflexionar sobre dos ideas que menciona el informe: gray data e information loss. En lugar de gray data yo lo llamaría más bien brown data en el sentido que implica que el conjunto de datos de entrada está hecho unos zorros y en teoría contiene cierta información pero en la práctica cada campo de las tablas de entrada es un chorizo de Cantimpalo del cual hay que inferir cosas. Un ejemplo de esto se puede encontrar en el Data Science Toolkit un conjunto de herramientas libres que hacen cosas como hallar el nombre de una persona en un documento de texto o adivinar el género leyendo el nombre. Information loss se refiere a la información que se descarta en las etapas de traspaso del nivel operativo al táctico y al estratégico.
Creo que vale la pena detenerse especialmente a reflexionar sobre dos ideas que menciona el informe: gray data e information loss. En lugar de gray data yo lo llamaría más bien brown data en el sentido que implica que el conjunto de datos de entrada está hecho unos zorros y en teoría contiene cierta información pero en la práctica cada campo de las tablas de entrada es un chorizo de Cantimpalo del cual hay que inferir cosas. Un ejemplo de esto se puede encontrar en el Data Science Toolkit un conjunto de herramientas libres que hacen cosas como hallar el nombre de una persona en un documento de texto o adivinar el género leyendo el nombre. Information loss se refiere a la información que se descarta en las etapas de traspaso del nivel operativo al táctico y al estratégico.





Pingback: Interdominios.com» Blog Interdominios » El Gray Data y la Inteligencia de los Negocios
Pingback: Del Software As A Service al Data As A Service, pero no mañana… | La Pastilla Roja
Pingback: El nuevo científico de datos | La Pastilla Roja